
Enhancing RAG through LlamaIndex’s Blueprint for Effective Embedding and LLM Fine-Tuning
Upgrading RAG Performance with LlamaIndex’s Guide to fine-tuning options, when to use it, how to use it correctly and the best practices.

When I started this post, I wondered if I should write another formal one, which is a guide on fine-tuning your RAG on specific data. However, given the abundance of existing articles on RAG fine-tuning, I questioned myself if there is a need for another. Of course, it will not just be another ordinary with 10-k reports which I’m sure you can find on the official document. I want to do something more practical such as fine-tune on your code repository or fine-tune on the official AWS Sagemaker document (because I’ve worked on it lately).
Then I sat down and started looking into LlamaIndex’s official document of the Finetuning session because I couldn’t just drop a Jupyter Notebook to a blog say “Here we go” and explain the notebook along the way — I needed some context, and even though I’ve been working with fine-tuning for ages but I figured a little refresher wouldn’t hurt. I'm glad I did! Going through that doc made me realize just how wild and overwhelming the whole LLM/RAG scene can be for newbies.

Spark: I should summarise all the fine-tuned options that LlamaIndex offer with a context of what it is, how and when to use it before diving into an in-depth or practical post. This will be a frequently updated article as soon as LlamaIndex update its document.
So in this post, I will walk through the fine-tuning option that is available from LlamaIndex. For each option, I will quickly talk about what it is, how to use it and when to use it along with a few examples or notes based on my experiment/experience when I worked with it.
If you are familiar with LlamaIndex’s fine-tuning already then feel free to skip this article, and if you are new in this domain then the upcoming content could be beneficial.
Just a heads up: I hope you’ve read my previous article. I explained all the concepts of building an LLM app with LlamaIndex. If you find it hard to follow or understand the content below, please refer back to my previous articles on how to build the first chatbot, the basics of LlamaIndex with how to use index, and how to use storage, and how to choose the right embedding model

Why do we need Finetuning?
Fine-tuning can be beneficial for improving the efficiency and effectiveness of a model. It can reduce training time and cost, as it does not require starting from scratch. Additionally, fine-tuning can increase performance and accuracy by leveraging the features and knowledge of the pre-trained model. It also provides access to tasks and domains that would otherwise be inaccessible, as it allows for transferring the pre-trained model to new scenarios. In other words, it’s all about getting better results, cutting down on weird outputs, remembering data better, and saving time and money.
The core of our toolkit revolves around in-context learning/retrieval augmentation, which involves using the models in inference mode and not training the models themselves.
While finetuning can be also used to “augment” a model with external data, finetuning can complement retrieval augmentation in a variety of ways:
Embedding Finetuning Benefits
Finetuning the embedding model can allow for more meaningful embedding representations over a training distribution of data –> which leads to better retrieval performance.
LLM Finetuning Benefits
Allow it to learn a style over a given dataset
Allow it to learn a DSL that might be less represented in the training data (e.g. SQL)
Allow it to correct hallucinations/errors that might be hard to fix through prompt engineering
Allow it to distill a better model (e.g. GPT-4) into a simpler/cheaper model (e.g. GPT-3.5, Llama 2)
In short, fine-tuning help to have better similarity search which is necessary for better data retrieval
Now, that is enough talking, let’s have a look into available options that are offered by LlamaIndex.
There are two main types of fine-tuning. The first one is fine-tuning embedding with the purpose of improving accuracy of data retrieval, the second one is fine-tuning LLM to inject the domain knowledge into existing LLM.
The first one is RAG-specific while the second one is general-purpose and no need for RAG to query if the fine-tuning for LLM is up-to-date with data
Finetuning Embeddings
Large language models (LLM) can handle a wide range of tasks, including sentiment analysis, information extraction, and question-answering. The correct architecture, a well-thought-out training process, and the availability of the entire internet for training data are what combine to make them adept at certain tasks.
An LLM is trained to generalize across many domains using these enormous amounts of data, producing a model that is generally excellent but lacks domain-specific knowledge. Here, fine-tuning becomes important.
The process of fine-tuning involves changing your language model to better suit the domain of your data. For instance, you want to process a lot of hospital paperwork about the patients so you might want to specialize your LLM on these kinds of texts.
Tip: you should always check the HuggingFace model to see whether someone has already fine-tuned a model on data that is comparable to yours before doing it yourself.
LlamaIndex’s guide on Finetuning embeddings contains three main steps:
Generating a synthetic question/answer dataset from your data
Finetuning the model
Evaluating the model.
Basic Fine-Tune Embeddings
Guide: can be found here
Steps summary:
Have data as train set and data as validation dataset, for example, 10k report of Lyft as train dataset and 10k report of Uber as validation dataset
2. Use the built-in function generate_qa_embedding_pairs to generate the question/answer of the training dataset. This step will call the LLM model (by default use OpenAI) to generate a synthetic dataset for the Lyft 10k report document
3. Use SentenceTransformersFinetuneEngine with HuggingFace model “BAAI/bge-small-en” to fine-tune
finetune_engine = SentenceTransformersFinetuneEngine(
train_dataset,
model_id="BAAI/bge-small-en",
model_output_path="test_model",
val_dataset=val_dataset,
)4. Evaluate by using the hit rate metric. This step simply uses the fine-tuned embedding model of “BAAI/bge-small-en” from step #3 on the 10k Uber and the base embedding model “BAAI/bge-small-en” on 10k Uber, then compares the result.
The evaluation process is vital and a must for any RAG app, you can always refer back to my previous post to know more about the technique of evaluation of the RAG pipeline with LlamaIndex

When to use it: this is a basic one, you should try it the first time to see if it improves the RAG performance compared to the base model
Finetuning an Adapter
This is an upgraded version of basic fine-tuned embeddings. This essentially means we have more control over the fine-tuned process. The basic fine-tuned embeddings just simply use out-of-box of whatever SentenceTransformersFinetuneEngine offer. If you are familiar with neural networks (in short NN), then you may be familiar with layer, stop loss, and ReLU activation. This Adapter is just like that, allowing us to have more control over the fine-tuned process.
Guide: can be found here
Steps summary:
Similar to step 1 of basic fine-tuning embeddings
Similar to step 2 of basic fine-tuning embeddings
Instead of using SentenceTransformersFinetuneEngine, we will use EmbeddingAdapterFinetuneEngine. You can add a layer as a parameter into EmbeddingAdapterFinetuneEngine with predefined TwoLayerNN like this
base_embed_model = resolve_embed_model("local:BAAI/bge-small-en")
adapter_model = TwoLayerNN(
384, # input dimension
1024, # hidden dimension
384, # output dimension
bias=True,
add_residual=True,
)
finetune_engine = EmbeddingAdapterFinetuneEngine(
train_dataset,
base_embed_model,
model_output_path="model5_output_test",
model_checkpoint_path="model5_ck",
adapter_model=adapter_model,
epochs=25,
verbose=True,
)
## if you need to load the model from the particular checkpoint, then use this
# load model from checkpoint in the midde
embed_model_2layer_s900 = AdapterEmbeddingModel(
base_embed_model,
"model5_ck/step_900",
TwoLayerNN,
)4. Similar to step 4 of basic fine-tuning embeddings
When to use it: if the basic does not give the result you expected then consider trying this one.
In my experience, unless you have work with NN before and understand the concepts such as ReLU or layers or stop loss, then you should go with this embedding approach in the first place. When you see the metric and you know what to do to optimize it, then use Adapter. Otherwise, the first basic approach is enough to give you a small boost of RAG.
Router Fine-tuning
I don’t find myself using this fine-tuning that frequently, in my understanding, this type of fine-tuning is good for a router query. But router query is very data-domain specific and adding this embedding only increases the complexity of RAG.
If you are unfamiliar with routers, this article may help.
A quick summary of the router: you cannot throw a bunch of the documents for embedding and then build retrieval on top of it. That naive approach will never get you any good result, not even a remotely acceptable result. So LlamaIndex introduced a wonderful concept called Router. Routers are an important step towards automated decision-making with LLMs and this essentially treats LLMs as a classifier

But the base router is, well, terrible sometimes with the match rate between query and index being terribly low. To handle this, LlamaIndex is now allowed to fine-tune routers. This will help to reduce the number of loops to run for each query, hence, expecting the result is faster. But the result is still sometimes terrible.

My opinion: LlamaIndex has introduced a concept called Multi-agent. Basically, for each document, you build multiple indexes on top of it such as VectorIndex, SummaryIndex, KeywordIndex, etc then give the metadata or description of each index, and then the agent is built on top of this with the metadata description to tell LLM what does this agent do. If you have 1 million documents, you have 1 million agents. Every time you do a query, LLMs need to go through 1 million agents to find out what is the best agent to use to answer your question. Hence, it is slow and not effective. To handle this issue, LlamaIndex has upgraded the current version to another one which is basically reranking during document (tool) retrieval Query planning tool that the agent can use to plan.
In my experiment, this approach is better than a router. I don’t fine myself using the router as often as I expected. But with this spark, I may try fine-tune routers + multi-agent to see if it boosts the accuracy
You can help yourself by reading through the document here
When to use it: only if your RAG is highly router-centric, otherwise, the ReAct agent or Multi-agent is a better approach.
Cross-Encoder Finetuning
A quick understanding of what is cross-encoder vs bi-encoder.
Put simply, Bi-Encoder is what we work with bi-encoder where a sentence A and sentence B will be converted into sentence embedding A1 and sentence embedding B1. These sentence embeddings can then be compared using cosine similarity.

In contrast, for a Cross-Encoder, we pass both sentences simultaneously to the Transformer network. It produces an output value between 0 and 1 indicating the similarity of the input sentence pair
A Cross-Encoder does not produce a sentence embedding. Also, we are not able to pass individual sentences to a Cross-Encoder.
As detailed in our paper, Cross-Encoders achieve better performances than Bi-Encoders. However, for many applications they are not practical as they do not produce embeddings we could e.g. index or efficiently compare using cosine similarity.
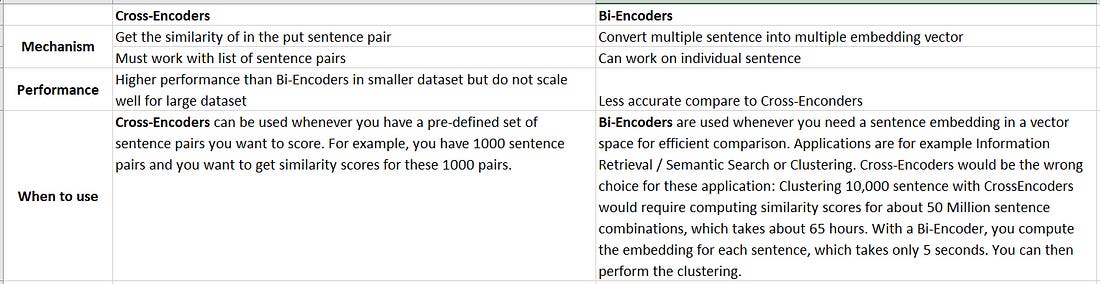
Cross-Encoders achieve higher performance than Bi-Encoders, however, they do not scale well for large datasets. Here, it can make sense to combine Cross- and Bi-Encoders, for example in Information Retrieval / Semantic Search scenarios: First, you use an efficient Bi-Encoder to retrieve e.g. the top-100 most similar sentences for a query. Then, you use a Cross-Encoder to re-rank these 100 hits by computing the score for every (query, hit) combination.
“So, I want to see the real use-case or example of it” you say:
If you search for “programming for data scientists”, a keyword search will find “An intro to programming for data scientists” with Bi-Encoders, but it won’t return “Python for Machine Learning use-cases”. This is where Cross-Encoders shine.
Action: please help yourself with this notebook
Fine-tuning LLMs
So you’ve gone through the Fine-tuning with embeddings, as noted, fine-tuning embeddings helps to improve the accuracy of data retrieval. If so, do we need fine-tuning LLMs?
Because not every time, you will need RAG. Developing a fully functional RAG is complicated at every step. Having a good RAG app requires a team combined of good software engineers to develop the front end and scalable back end, excellent data engineers to handle the data pipeline and multiple databases that are used for developing RAG, a few good machine learning engineers + data scientists to develop a model and do experiment on text chunk, embedding performance, good data retrieval method, then synthetic data, router, agents, etc. Not to mention you will need a good MLOps to monitor the performance of RAG.
Spark: What if you can simplify all of these methods by gradually fine-tuning LLMs on new data? Make it a ChatGPT but fine-tune on your own data. Would it be easier?
Well, not quite, do you have a big budget to fine-tune or retrain LLMs gradually?
Not so many organizations want to invest a lot of money into LLMs until they see a clear sign of how it is gonna help their company. Most of the LLMs/RAG are mainly PoC. It can deal with a small dataset and handle well in a very specific situation but struggles to scale or handle the real-life use case.
But let’s assume you have the capital to fine-tune LLMs regularly. How do we do it?
LlamaIndex has multiple options to help you fine-tune your LLMs. The main purpose is to improve the lower-tier model to surpass the higher-tier model. Say GPT-4 is super good for your app but it will bankrupt the company because it is expensive. GPT-3.5 is cheaper with acceptable performance but you want the GPT-4 performance to make your client happy. Then you may think of fine-tuning LLMs.
But first, Why Fine-tune LLMs
As mentioned, Fine-tuning not only improves the performance of a base model, but a smaller (fine-tuned) model can often outperform larger (more expensive) models on the set of tasks on which it was trained. This was demonstrated by OpenAI with their first generation “InstructGPT” models, where the 1.3B parameter InstructGPT model completions were preferred over the 175B parameter GPT-3 base model despite being 100x smaller.
A big one is LLMs have a finite context window. Thus, the model may perform sub-optimally on tasks that require a large knowledge base or domain-specific information. Fine-tuned models can avoid this issue by “learning” this information during the fine-tuning process or in other words, updating your model with the newest data. GPT-4 only have knowledge up until 2022, not alone your corporate data. Fine-tune LLMs will update the model with your private data and reduce hallucinations, you also don’t need RAG as fine-tuned LLMs are already up-to-date with your data.
I’m sold, let’s fine-tune LLMs
Where to start? LlmaIndex offers a few notebooks that mainly show how to fine-tune GPT-3.5 to distil GPT-4. But it does not have to be OpenAI’s product. You can fine-tune other LLMs such as zephyr-7b-alpha or mistralai/Mistral-7B-v0.1 to distil GPT-4. The best part, you can even host your own fine-tune model.
Let’s start with something simple first GPT-3.5 Fine-tuning Notebook (Colab)
Then you can go to Fine-tuning a gpt-3.5 ReAct Agent on Better Chain of Thought.
If you find it hard to understand the ReAct Agent then this guide may help.
There are hundreds of things if you want to go in-depth into fine-tuning LLMs and no short article can explain. I don’t intend to cover everything about fine-tuning LLM, this article is mainly about the available options of fine-tuning with LlamaIndex. I may write an in-depth practice for each type of embedding but I do feel LlamaIndex’s official documents are good enough. If you want me to put on some practice with the real use case of using embedding then feel free to leave a request comment.
Summary
This quick and short post is just a quick glimpse of different types of fine-tuning data, when to use it, how to use it and a quick guide with LlamaInex.
In summary, fine-tuning is more about changing the behavior of a language model, while embedding is more about extracting useful information from text.
Improving RAG is hard, there are multiple steps to it and the most important steps in my experience that can improve RAG dramatically are text chunk and embedding. Hence, fine-tuning the embedding model is a necessary (if not a must) step. In addition, fine-tuning LLMs will update existing LLM’s behaviour, hence, reducing the hallucinations in the response and better synthetic answers.
I strongly advise starting with fine-tuning embedding first and gradually fine-tuning LLM into your RAG if necessary. If you need to know more about techniques to improve RAG, then you can have a look into this article.
So you want to improve your RAG pipeline

LLMs are a fantastic innovation, but they have one major flaw. They have cut-off knowledge and a tendency to make up facts and create stuff out of thin air. The danger is LLMs always sound confident with the response and we only need to tweak the prompt a little bit to fool LLMs.
In the next post, I will cover the topic of how to improve RAG with a mix of unstructured and structured data, especially data with free-form tables. So follow and subscribe to not miss out.
❤ If you found this post helpful, I’d greatly appreciate your support by giving it a heart. It means a lot to me and demonstrates the value of my work. Additionally, you can subscribe to my substack as I will cover more in-depth LLM development in that channel
Want to Connect?
If you need to reach out, don't hesitate to drop me a message via my
Twitter or LinkedIn and subscribe to my Substack, as I will cover
more learning practices, especially the path of developing LLM
in depth in my Substack channel.References
https://gpt-index.readthedocs.io/en/latest/end_to_end_tutorials/finetuning.html