
So you want to improve your RAG pipeline
Ways to go from prototype to production with LlamaIndex

LLMs are a fantastic innovation, but they have one major flaw. They have cut-off knowledge and a tendency to make up facts and create stuff out of thin air. The danger is LLMs always sound confident with the response and we only need to tweak the prompt a little bit to fool LLMs.
To resolve this issue, here comes the RAG. RAG makes LLMs significantly more useful by providing factual context for them to use when answering queries.

With roughly a few lines of code and a quick-start guide to a framework like LlamaIndex, anyone can construct a chatbot to chat with your private documents or even better, can build a new entire agent that is capable of searching on the internet.
BUT
You never have production-ready if only follow the quick guide
These five lines of code will not result in a very functional bot. RAG is simple to prototype but difficult to "production," or bring to the point where customers would find it satisfactory. RAG might operate at an okay level after a little tutorial. However, it frequently requires some considerable testing and strategy to optimize to bridge the real production grade. Best practices are still being developed and can change based on the use case. Finding the best practices is worthwhile, from different indexing techniques to embedding algorithms or changing the LLM models.
In this post, I will discuss the calibre of RAG systems. It is designed for RAG builders who want to bridge the performance gap between entry-level setups and production-level performance.
There are 3 stages of the RAG pipeline:
Indexing Stage
Querying Stage
Responding Stage
In this post, improving here is a general term and it relates to anything that can be used to improve the pipeline, usually refers to raising the percentage of queries that the system: Identifies the relevant context and produces a suitable answer.
I'll presume the reader is already familiar with LlamaIndex and an RAG pipeline. If not, you can always refer to all of my previous posts in my substack, start with

then how to use Llama’s index, how to use storage with LlamaIndex, choose the right embedding model and finally deploy in production
It will also be assumed that you have a rudimentary understanding of LlamaIndex frameworks, which are frequently used to create these tools. However, the concepts covered here are not framework-specific.
In the upcoming post, I will cover the End-to-End assessment and Evaluation of the RAG pipeline with LlamaIndex, so subscribe to not miss out on the future post.
How to boost Retrieval Augmented Generation Performance
Let’s see what we can do to improve RAG performance.
1. Like Machine Learning and Data Scientists: you must clean your data
RAG links your data to an LLM's capabilities. Your system will suffer if the data you use is unclear, either in terms of content or presentation. Your retrieval will have a difficult time locating the proper context if you are employing data that has redundant or conflicting information. And when it occurs, the LLM's generation step might not be as good as it could be. Imagine you're creating a chatbot for the corporate documentation of your company and it isn't performing effectively. The data you are feeding the system should be the first item you examine.
Questions to ask such as: Are the documents separated logically? Are subjects covered all in one spot or scattered throughout? Are there any duplicated documents? Should you get the latest document updated or the history of the documents?
This procedure can be as straightforward as manually integrating documents that are related to the same thing, but you can go beyond. Using the LLM to make summaries of all the documents presented as context is one of the more inventive strategies I've seen. After conducting a search over these summaries, the retrieval phase can then only get into the details when necessary. This is even a built-in abstraction in some frameworks.
2. What are the suitable index types?
I can’t really tell if there is one index type that fits all. There is no perfect solution and you only can find the best index types for your set of documents by trial and trial. Period.
Indexing is a core pillar of LlamaIndex, RAG is often approached via similarity searches and embeddings. When a query comes in, discover related context components by breaking up the data into smaller chunks and embedding everything. Although it works great, this isn't always the greatest strategy. Will questions be about specific objects, like those found in an online store? Consider looking at keyword-based searches or graph knowledge. Numerous applications take advantage of hybrids, therefore it need not be either/or. For instance, you might rely on embeddings for general customer support while using a keyword-based index or summary index or graph knowledge index for questions about a particular product.
3. How to handle big and long documents.
We already know there is a limitation of the max token when calling OpenAI API, hence, the naive approach to feeding a document to OpenAI API and expecting a response from it is a little farfetched. Not only it is not possible because of token limitation but also it is expensive when you need to send max token every time.
Context data processing is a crucial component of creating a RAG system. Frameworks enable you to escape from the chunking process by abstracting it away. But you should give it some thought. Chunk size is important. Investigate what functions best for your application. In general, retrieval is frequently enhanced by smaller chunks, while creation may suffer from a lack of contextual information. There are numerous ways to go about chunking. Approaching things in a blind manner is the only thing that doesn't work. Some approaches to thinking about the chunk side are recommended by PineCone. I don’t have any questions to ask when it comes to breaking down the document into small chunks. I usually just loop through each set and find the best fit.
4. Metadata is important
It is a very effective strategy to improve your RAG pipeline, especially with those pipelines that have a sub-query or router query engine. Because it allows you to filter by recency, date is a popular meta-data tag to include. Consider creating an app that enables users to look up their legal document history. The latest documents will probably be more correct and up-to-date information. However, we don't know which ones will be the most comparable to the user's query from an embedding perspective. This raises the question of how to create RAG while keeping in mind the fundamental idea of comparable and relevant. You can add the date to the meta-data of each document and then, when retrieving, give preference to the most current context. A class of Node Post-Processors that is integrated into LlamaIndex can assist with this.
5. Sub Query or Query Routing
We just spoke of sub-query and routing in #4. Once you find vector index alone cannot handle all of your requirements then having more than one index for a single document is frequently helpful: such as Vector Index, Summary Index, List Index, etc has their own purpose and stacking those index together will boost your RAG performance. Afterwards, you direct incoming queries to the correct index. You might, for instance, have an index that works well for date-sensitive inquiries, another that handles specific keywords, and still another that covers summary questions. A single index's performance across all of these characteristics will be compromised if you attempt to optimize it for all of them. You can instead direct the query to the appropriate index.
LlamaIndex just introduced OpenAI Agent lately, this technique + stacking index will boost your RAG to another level.
6. If trying multiple embedding does not work, then fine-tune your embedding model
The typical retrieval strategy for RAG is embedding-based similarity. Your information has been divided up and placed inside the index. A query is also embedded when it is submitted for comparison with the index's embedding. But how is the pre-trained embedding done? In the tutorial, you always see text-embedding-ada-002 which is for general purpose, but if you have been in this area for a while, you will know HuggingFace’s MTEB leaderboard where you find the best embedding model at the time of writing is bge-large-en-v1.5
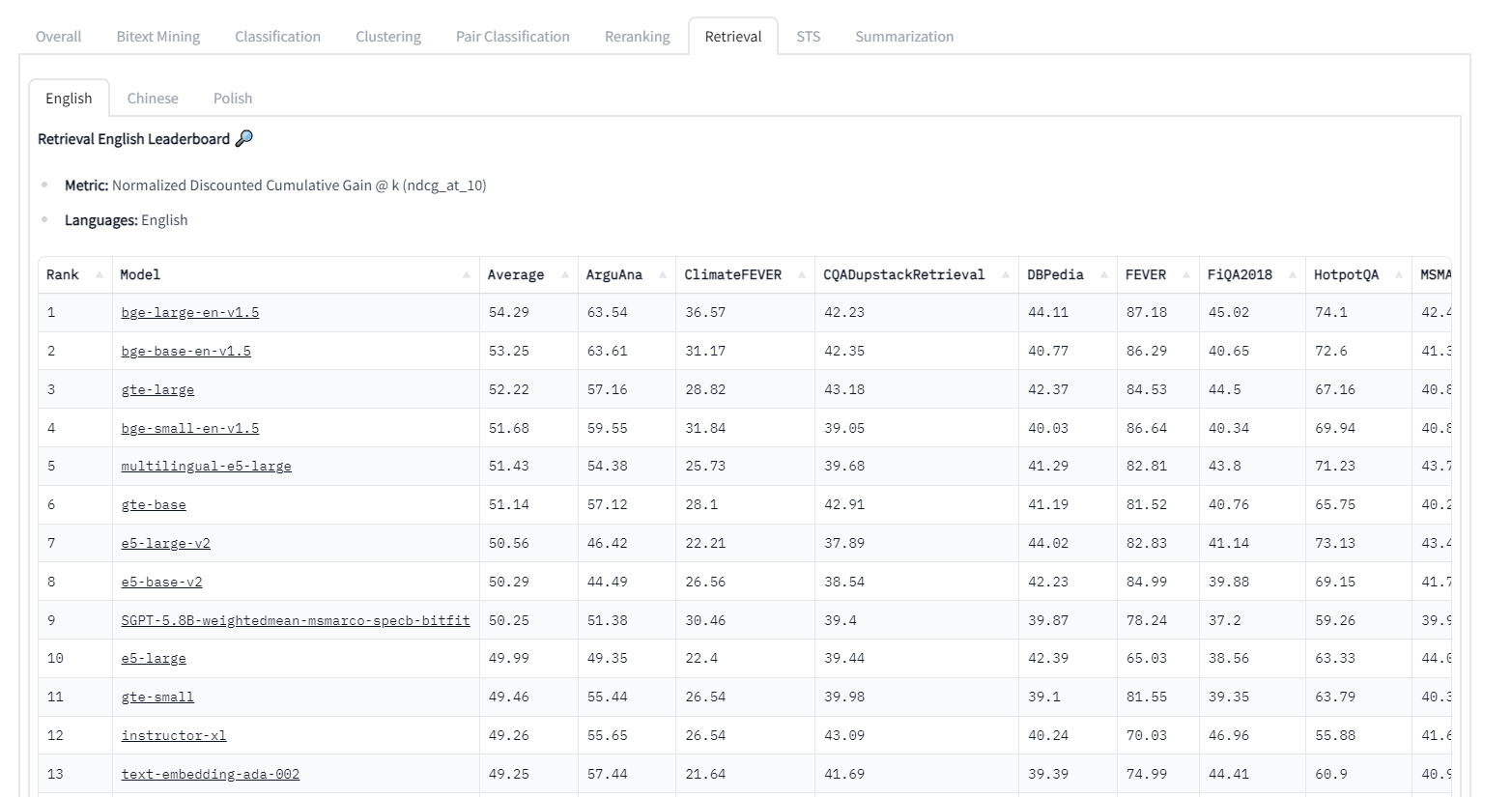
The problem here is that your context might not very well align with what the pre-trained model considers to be similar in embedding space. Consider that you are handling hospital paperwork. You would like your embedding to base its determination of similarity less on general terms like SOAP Notes, EMR/EHR, STAT, Code Blue, CT Scan, MRI or ICD-10.
You can fix this problem by tweaking your embedding model. This will increase your retrieval metrics. This takes a little more work, but it can significantly improve your retrieval efficiency. Since LlamaIndex can assist you in creating a training set, the process is simpler than you may imagine. You can check this overview post for more detail
7. Prompt Engineer?
Hot job title in the future, maybe? But for now, you can experiment with different prompts and try different things. If the LLM can't identify a suitable solution in the context, you can even modify the RAG such that it allows the LLM to rely on its own knowledge. You can modify the prompt to help limit the kinds of questions it accepts, for example, by telling it how to reply to questions that are subjective. Overwriting the prompt will at the very least give the LLM context for the tasks it is performing.
8. Evaluation Dev Tools
With the growing ecosystems and frameworks built around LlamaIndex or Langchain, you can find helpful evaluation tools such as Trulens or DeepEvalor Ragas. Or elsewhere like Rivet - is a tool that offers a visual interface to aid in the development of complicated agents. Every day, new tools are introduced, so it's important to experiment to see which ones will benefit your workflow.
Other things to consider
Few other techniques to consider when improving your RAG pipeline such as reranking or query transformation. These techniques have been around for quite a while and are still helpful in some cases.
Summary
RAG is both incredibly simple to use and incredibly difficult to use correctly, building with it may be challenging. The methods I've listed above are intended to provide you with some ideas for how to close the gap. It takes experimentation, trial, and error to figure out which of these principles works best in each specific situation. In this post, I didn't go into detail about evaluation and how to gauge a system's success. In spite of the fact that evaluation is currently more of an art than a science, it's crucial to build up a system that you can monitor regularly. Only by doing this then you can determine whether the adjustments you are making are having an impact.
📅 There is a long-form evaluation end-to-end assessment of RAG with LlamaIndex article coming, so subscribe to not miss out.
❤️ If you found this post helpful, I'd greatly appreciate your support by giving it a heart. It means a lot to me and demonstrates the value of my work. Additionally, if you'd like to further support my efforts, you can consider a small contribution through a paid subscription.