
Choosing the Right Embedding Model: A Guide for LLM Applications
Optimizing LLM Applications with Vector Embeddings, affordable alternatives to OpenAI’s API and how we move from LlamaIndex to Langchain

So you may think that I’m gonna write part 2 of the series on how to build a great chatbot app that is different from 99% of tutorials on the internet. Guess what, it is not gonna happen in this post. I’m sorry in advance but there is a reason why I’m not rushing into part 2 yet and I shall explain to you.
Zero to One: A Guide to Building a First PDF Chatbot with LangChain & LlamaIndex - Part 1

Welcome to Part 1 of our engineering series on building a PDF chatbot with LangChain and LlamaIndex. Don't worry, you don't need to be a mad scientist or a big bank account to build and train a model. With the rise of Large Language Models (LLMs) such as ChatGPT and GPT-3, it's now easier than ever to build intelligent chatbots that are smarter than you…
Yep, I know you’ve been eagerly awaiting the second part of our journey in building an amazing AI-powered chatbot using Large Language Models (LLMs). But, you know what? Something happened while I was working on my very own LLM app. I discovered that each embedding model I experimented with produced different and intriguing results. Some were simply so good, while others fell a bit short of expectations. That got me thinking:
how can we truly grasp the power of these embedding models and understand their impact on chatbot performance?
So, I couldn’t resist the urge to share my insights with you through this article. Trust me, it’s well worth your time to equip yourself with this essential knowledge before diving headfirst into your own projects. After all, every great house is built upon a solid foundation, right? Now, don’t worry, I promise this won’t be a dull university lecture. I’ve made sure to include plenty of practical tutorials and engaging examples to keep you excited throughout the read. Similar to the post on how to use Llamaindex’s Index correctly, I will take the same approach for this article

So, without further ado, let’s embark on this fascinating journey together and uncover the secrets of embedding models. Let’s get started!
What is Vector Embedding
In the realm of AI chatbot development, vector embedding plays a pivotal role in capturing the essence of textual information. At its core, vector embedding refers to the process of representing words, sentences, or even entire documents as dense, low-dimensional vectors in a mathematical space. Unlike traditional methods that rely on sparse representations like one-hot encoding, vector embeddings encapsulate the semantic relationships between words and enable algorithms to comprehend their contextual meaning.
The importance of vector embedding lies in its ability to transform the raw text into a numerical representation that algorithms can comprehend and reason with. This transformative process not only facilitates various natural language processing (NLP) tasks but also serves as a fundamental building block for large language models. Vector embeddings empower these models to leverage the rich semantic information embedded within the textual data, enabling them to generate more coherent and contextually appropriate responses.
How Vector Embeddings Capture Semantic Information
Vector embeddings capture semantic information by representing words, sentences, or documents as dense vectors in a mathematical space. These vectors are designed to encode contextual and semantic relationships between textual elements, allowing for more nuanced understanding and analysis.
The process of capturing semantic information begins with training a vector embedding model on a large corpus of text. During training, the model learns to assign vectors to words or sequences of words in a way that reflects their semantic similarity and context. This is achieved by analyzing the co-occurrence patterns of words in the training data.

For example, in word embeddings, such as Word2Vec or GloVe, words that often appear together in similar contexts are represented by vectors that are positioned closer to one another in the embedding space. This proximity reflects their semantic similarity. By leveraging the statistical patterns of word usage across a vast dataset, these embeddings capture semantic relationships, such as synonyms, analogies, or even broader concepts like gender or sentiment.
If you wish to learn more about in-depth of vector embedding, you may find this post super helpful, thank you Partee for doing such a great job explaining vector embedding: https://partee.io/2022/08/11/vector-embeddings/
Importance of Vector Embeddings for Large Language Model Applications
Vector embeddings hold immense importance in the realm of large language model (LLM) applications. LLMs, such as GPT-3, BERT, or Transformer-based models, have gained significant attention and popularity due to their remarkable ability to generate coherent and contextually appropriate responses.
The success of LLMs hinges on their understanding of the semantic intricacies of natural language. This is where vector embeddings come into play. By utilizing vector embeddings, LLMs can leverage the rich semantic information embedded within textual data, enabling them to generate more sophisticated and context-aware responses.
Vector embeddings serve as a bridge between the raw textual input and the language model’s neural network. Instead of feeding the model with discrete words or characters, the embeddings provide a continuous representation that captures the meaning and context of the input. This allows LLMs to operate at a higher level of language understanding and produce more coherent and contextually appropriate outputs.
The importance of vector embeddings for LLMs extends beyond language generation. These embeddings also facilitate a range of downstream tasks, such as sentiment analysis, named entity recognition, text classification, and more. By incorporating pre-trained vector embeddings, LLMs can leverage the knowledge captured during the embedding training process, leading to improved performance on these tasks.
Moreover, vector embeddings enable transfer learning and fine-tuning in LLMs. Pre-trained embeddings can be shared across different models or even different domains, providing a starting point for training models on specific tasks or datasets. This transfer of knowledge allows for faster training, improved generalization, and better performance on specialized tasks.
By now, you should have a solid grasp of vector embedding and its significance in developing LLM applications. In the following sections, let’s dive straight into comparing different embedding models. If you’re like me, someone seeking alternative options to OpenAI’s API due to too poor to pay for it :(, this guide will help you choose the most suitable embedding model for your specific task.
Again, I will leave all the hard work to explain vector embedding to experts here. My job at this post is to bring some practical approach and high-level knowledge, so let’s get started.
LlamaIndex Embedding Options
By default, LlamaIndex uses OpenAI’s text-embedding-ada-002 as a default embedding vector model. Even OpenAI also suggest using this model for all general purpose because according to them, this model is and I quote “cheapest and fastest” than other models. But is it though?
If you want to look into different embedding models that OpenAI offers, you can find them here and here. But how cheap it is exactly?
You can think of tokens as pieces of words used for natural language processing. For English text, 1 token is approximately 4 characters or 0.75 words. As a point of reference, the collected works of Shakespeare are about 900,000 words or 1.2M tokens.

Only $0.0004 / 1K token is very cheap at first glance. However, in reality, it can quickly become expensive. Let me illustrate with an example:
Suppose you want to build a chatbot to chat with your corporate’s doc and you have 10,000,000 files, with an average text length of 20,000 tokens. In this scenario, you would end up spending: 10,000,000 x 20,000 x 0.0004 = $80,000 solely on embeddings
While the OpenAI model is indeed perfect for general purposes even with the text-embedding-ada-002. If you only build an app to read your file, then it is fine but imagine running a startup in that the user submits that amount of tokens monthly :( of course, you will charge customers monthly but still not profitable since you pay a decent trunk for the API already. Not to mention that
OpenAI’s API is slow sometimes due to huge requests
You may want to call this API multiple times for the same document since you may have multiple indexes built on top of each other or separately.
That is why, we will explore other kinds of completely free models that we can deploy on our own.
Lucky for us, LlamaIndex does allow us to use other embedding models instead of using OpenAI. There are two options you can go with if you don’t want to use OpenAI’s embedding model
Use HuggingFace and all the available embedding models that HuggingFace offers here
Bring your own embedding model. You can either publish your model to HuggingFace and go back to step 1 or if you want to keep your model private then there is a lot of work you need to do. You need to build a custom code that uses LlamaIndex’s Retrieval instead of using LlamaIndex's default option which only supports OpenAI embedding and HuggingFace Embedding with Langchain wrap at the moment.
How to find the right embedding for your task?
If you still want to use OpenAI because you can afford it and want to use the leader of the field, then you can find all model that is suitable for your task here

While OpenAI’s embedding model is widely known, it’s essential to recognize that there are alternative options available. Hugging Face, a renowned platform in the NLP community hosts the Massive Text Embedding Benchmark (MTEB) Leaderboard. This leaderboard serves as a valuable resource for evaluating the performance of various text embedding models across diverse embedding tasks. For a comprehensive understanding of the MTEB Leaderboard and its significance, I recommend referring to the “MTEB: Massive Text Embedding Benchmark” available at (https://huggingface.co/spaces/mteb). It provides a thorough explanation of the leaderboard’s purpose and insights into different text embedding models. Exploring this resource will broaden your understanding of the text embedding landscape and assist you in making informed decisions for your embedding needs.

As you can see, the text-embedding-ada-002 is ranked 6th only in terms of overall. But does that mean we should use e5-large-v2 for all of our tasks? Not quite !!!!
Since we are building question-answering based on our knowledge base, we should pay attention to the tab Retrieval.

And the winner is, not surprisingly the mighty text-embedding-ada-002. The instructor-large is only 0.39 points behind while the king e5-large-v2 is not even made to the top 10.
It is worth noting that the most complicated embedding model text-search-davinci-001 falls out of the top 20 despite the fact that OpenAI claims it performs Text similarity models and Text search models better than other relative models with costs 500x more than ada-002.
That is very interesting because now we do have some open-source models that can perform similarly to the mighty text-embedding-ada-002. Let’s try it, shall we?
Custom Embedding Model
As previously stated, we will employ the instructor-large model provided by HuggingFace. For the sake of a straightforward demonstration, I will utilize ChromaDB instead of Pinecone. Should you require a refresher on index storage, please refer to my previous post.
LlamaIndex: Comprehensive guide on storage

Index store, vector store or embedding store and document store. In my third post of the PDF AI Chatbot building series, my intention was to dive deeper into the practical implementation discussed in part 2. However, as I continue writing, I realize the crucial significance of having a reliable storage system for your application. Unfortunately, when it …
Let’s start coding.
Import necessary stuff
import logging
import sys
import os
os.environ["OPENAI_API_KEY"] = "<your_openai_api_key>"
from llama_index import SimpleDirectoryReader, LLMPredictor, ServiceContext, StorageContext, LangchainEmbedding
from llama_index import GPTVectorStoreIndex
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.embeddings.openai import OpenAIEmbeddings
from llama_index import ResponseSynthesizer
Load the instructor-large as embedding and storage context
import chromadb
from chromadb.config import Settings
chroma_client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet",
persist_directory="./storage/vector_storage/chormadb/"
))
collection = chroma_client.create_collection("general_knowledge")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
## init llm model
llm_predictor_chat = LLMPredictor(llm=ChatOpenAI(temperature=0.2, model_name="gpt-3.5-turbo"))
## load the model
model_id = "hkunlp/instructor-large"
embed_model = LangchainEmbedding(HuggingFaceEmbeddings(model_name=model_id))
## init storage context and service context
storage_context = StorageContext.from_defaults(index_store=index_store, vector_store=vector_store)
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor_chat, embed_model=embed_model)Get some dummy data
from pathlib import Path
import requests
wiki_titles = ["Toronto", "Seattle", "Chicago", "Boston", "Houston", "New York City"]
for title in wiki_titles:
response = requests.get(
'https://en.wikipedia.org/w/api.php',
params={
'action': 'query',
'format': 'json',
'titles': title,
'prop': 'extracts',
# 'exintro': True,
'explaintext': True,
}
).json()
page = next(iter(response['query']['pages'].values()))
wiki_text = page['extract']
data_path = Path('data')
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", 'w', encoding="utf-8") as fp:
fp.write(wiki_text)Read all the documents. I only use New York and Houston for comparison.
docs= ['New York City','Houston.txt']
all_docs = {}
for d in docs:
doc = SimpleDirectoryReader(input_files=[f"./data/{d}"]).load_data()
nodes = parser.get_nodes_from_documents(doc)
doc_id = d.replace(" ","_")
doc[0].doc_id = d
## this can be used for metadata filtering if need
extra_info = {"id":d}
doc[0].extra_info = extra_info
all_docs[d] = docCreate the index. This will create a mighty GPTVectorStoreIndex. You can try with other indexes if you want. Again, I have written a very comprehensive article on what other indexes do. You can find it here
index_existed = False
for d in all_docs.keys():
print(f"Creating/Updating index {d}")
if index_existed:
## update index
print(f"Updating index: {d}")
# index_node.insert_nodes(all_nodes[d])
index.insert(all_docs[d][0])
else:
print(f"Creating new index: {d}")
index = GPTVectorStoreIndex.from_documents(
all_docs[d],
service_context=service_context,
storage_context=storage_context
)
index_existed = TrueNow, let’s experiment with a few queries
index.as_query_engine().query("What is population of New York?")
That is correct, this query just simply finds the population of New York City from the document.
We will do it again with Houston city
index.as_query_engine().query("What is population of Houston?")
Too easy, now let’s do something harder. I will ask the question of comparing the population between these two cities. We expect to have a result something like New York City has a large population compared to Houston.
index.as_query_engine().query("Compare the population of New York and Houston?")And the result?

What is disappointing?
The question does not provide information about the population of Houston, so it cannot be answered.
What, but you did say the population of Houston is 2,304,580 as of 2020.
What did we do wrong here? is LLM shockingly stupid? Should we change the embedding model to something else like OpenAI text-embedding-ada?
I’ve asked that questions and done a lot of experiments and frankly, it does not help at all. The thing is, the index.as_query_engine() is a default function. For a query like this, you need to customize your query engine to make it perform better. So, instead of using the as_query_engine() by default, we will use the custom retriever and with custom response modes.
For more information, you can find the details of the retriever and query engine
Pay attention on how you create the query engine cause it will vastly impact to the result
Before changing the code, here is a quick summary
Retrievers are responsible for fetching the most relevant context given a user query (or chat message). While query engine is a generic interface that allows you to ask question over your data. A query engine takes in a natural language query, and returns a rich response. It is most often (but not always) built on one or many Indices via Retrievers. You can compose multiple query engines to achieve more advanced capability.
Let’s change the code.
# configure retriever
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
# this will simple do the vector search and return the top 2 similarity
# with the question being asked.
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=2,
)
# configure response synthesizer
response_synthesizer = ResponseSynthesizer.from_args(verbose=True)
## if you nee to pass response mode
# response_synthesizer = ResponseSynthesizer.from_args(
# response_mode='tree_summarize',
# verbose=True)
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
# query
response = query_engine.query("Compare the population of New York and Houston.")
responseAnd the result
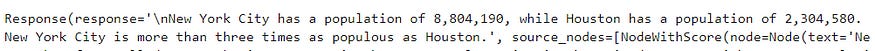
New York City has a population of 8,804,190, while Houston has a population of 2,304,580. New York City is more than three times as populous as Houston.
That is too good. With just a simple change, we now can answer the comparison question based on the general knowledge from the documents we feed.
If you wonder what is tree_summary in the ResponseSynthesizer, here is a quick summary
default: “create and refine” an answer by sequentially going through each retrievedNode; This makes a separate LLM call per Node. Good for more detailed answers.compact: “compact” the prompt during each LLM call by stuffing as manyNodetext chunks that can fit within the maximum prompt size. If there are too many chunks to stuff in one prompt, “create and refine” an answer by going through multiple prompts.tree_summarize: Given a set ofNodeobjects and the query, recursively construct a tree and return the root node as the response. Good for summarization purposes.no_text: Only runs the retriever to fetch the nodes that would have been sent to the LLM, without actually sending them. Then can be inspected by checkingresponse.source_nodes. The response object is covered in more detail in Section 5.accumulate: Given a set ofNodeobjects and the query, apply the query to eachNodetext chunk while accumulating the responses into an array. Returns a concatenated string of all responses. Good for when you need to run the same query separately against each text chunk.
The default mode is good enough for most of the cases.
Now, let’s try something more spicy.
# query
response = query_engine.query("""
Compare the population of New York and Houston.
What is the percentage difference between two populations?
""")Here, I asked a similar question but also ask the LLM model to spit the percentage difference between the two populations. And here is the result
The population of New York City in 2020 was 8,804,190, while the population of Houston in 2020 was 2,320,268. This means that the population of New York City is approximately 278% larger than the population of Houston.
It’s quite amusing to witness how LLM excels at retrieving information but falls short in accurately calculating numbers. For instance, the state “New York City is approximately 278% larger than the population of Houston.”
is correct but we are not asking how the bigger population of New York compare to Houston. We are asking about the “percentage difference” between the two populations.
So, how do we find the percentage difference (% difference calculator) between two positive numbers greater than 0 anyway?
Here is the correct formula for V1 and V2, assuming V1 is bigger than V2
By following this formula, we should get the number is approximately: 117.017% difference
So how do we fix the problem?
LlamaIndex proves to be exceptionally proficient in answering questions related to documents. It seems that the entire project is centred around this purpose, enabling effortless inquiry atop a comprehensive collection of documents, with LlamaIndex flawlessly handling the task at hand.
In order to overcome this limitation, we will need to delve into a significantly larger project known as Langchain. It is ironic, considering I initially mentioned in my first post that we would be building the app using LlamaIndex. However, we have encountered a major obstacle, and as per the fundamental principle of all startups — failing fast and pivoting — we must seek a more suitable alternative that aligns with our requirements.

If you find this to be a waste of time, allow me to offer a few motivational quotes to rekindle your enthusiasm: :)
A person who never made a mistake never tried anything new. — Albert Einstein
If you’re not failing every now and again, it’s a sign you’re not doing anything very innovative. — Woody Allen
Fail often so you can succeed sooner. — Tom Kelley
Hello Langchain
Trust me, it is not another typical project on how to build LLM apps with Langchain, we have too many articles and videos about that already. It is kinda boring if I have to do it again. If you don’t know what is Langchain, just do a quick Google search and spend a few days on all the tutorials and videos and go through the official document. If you know enough about Langchain already, that is good to process further.
As this article is long already, I will just post a code with a detailed explanation.
In short, we will use the following component of Langchain
Vector Storage ( LLM Database ): similar to LlamaIndex vector storage
Langchain’s Agent: this is what made Langchain popular
Langchain’s chain: RetrievalQA is made for question answering only.
Langchain’s chain: LLMMathChain is used when you need to answer questions about math.
Now, I know it is a lot to take in. Again, please go through the official documents to understand what are the components about. I will find some time to put on all the Langchain tutorials/articles/videos from beginner to advanced in future posts. So please subscribe and follow to get more :)
Langchain boasts incredible power, enabling you to construct virtually any LLM application you can envision. Unlike LlamaIndex, which is solely focused on LLM applications for documents, Langchain offers a plethora of capabilities. It can assist you in developing various functionalities such as internet search, result consolidation, API invocation, mathematical computations, even complex mathematical operations, and a whole host of other possibilities.
Let’s get into it
import logging
import sys
import os
os.environ["OPENAI_API_KEY"] = "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"
## load all the necessary components
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain.document_loaders import UnstructuredFileLoaderUse a custom embedding
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.embeddings.openai import OpenAIEmbeddings
model_id = "hkunlp/instructor-large"
embed_model = HuggingFaceEmbeddings(model_name=model_id)
vectorstore = Chroma("langchain_store", embed_model)Load the documents and add them to the vector store
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs= ['New York City','Houston.txt']
all_docs = []
for d in docs:
print(f"#### Loading data: {d}")
doc = UnstructuredFileLoader(f"./data/{d}", strategy="hi_res").load()
doc = text_splitter.split_documents(doc)
all_docs.extend(doc)
## add to vector store
vectorstore.add_documents(all_docs)Create the question-answering chain
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(temperature=0.2,model_name='gpt-3.5-turbo'),
chain_type="stuff",
retriever=vectorstore.as_retriever())
result = qa({"query": "Compare the population of New York and Houston. What is the percentage difference between two populations?"})
resultAnd the result:
According to the 2020 U.S. census, New York City has a population of 8,804,190, while Houston has a population of 2,304,580. The percentage difference between the two populations is approximately 282%
Still, give us the 282% out of nowhere. Let’s fix it with the LLM-math chain and agent.
Add Math Chain and Agent
from langchain import OpenAI, LLMMathChain
llm = OpenAI(temperature=0)
llm_math = LLMMathChain.from_llm(llm, verbose=True)
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
from langchain.tools import BaseTool
tools = [
Tool(
name="general knowledge",
func=qa.run,
description="useful for when you need to answer questions about the documents in the database"
),
Tool(
name="llm-math",
func=llm_math.run,
description="Useful for when you need to answer questions about math."
)
]
agent = initialize_agent(tools, ChatOpenAI(temperature=0.2,model_name='gpt-3.5-turbo'),
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("""Compare the population of New York and Houston.
What is the percentage difference between two populations?""")And here is the result:

This is so good, you see the agent will first find the information from the general knowledge tool to get the population of the two cities. After the first step, it uses LLM-math to calculate the percentage difference between two numbers.
Do you see how smart it is? It is smart enough to know what tool is used for what purpose. That is why we go all in for Langchain guys :)
As I have stated, Langchain is much much bigger than LlamaIndex and Langchain project focuses more on creating AGI applications as it supposes a lot of utilities such as web browser, call the API with OpenAPI model, etc.
It does not make sense for me to create yet another Langchain tutorial. I trust you guys can do it by looking into the official document. I will find some time to consolidate all the Langchain tutorials and videos from beginner to advance. In the meantime, I will upgrade my PC and start writing the next practical post. And this time, it is gonna be a part 2.
— -
If you do like this article, please give it a like and subscribe for more upcoming posts in the future. If you have any questions, please leave a comment, I will try to answer as soon as possible.
If you need to reach out, don’t hesitate to drop me a message via my Twitter or my LinkedIn and subscribe to my substack as I will cover more learning practice in depth in my substack channel.
References
Langchain: https://python.langchain.com/en/latest/index.html
LlamaIndex: https://gpt-index.readthedocs.io/en/latest/index.html
Vector Embedding: https://partee.io/2022/08/11/vector-embeddings/
OpenAI Embedding: https://openai.com/blog/introducing-text-and-code-embeddings
OpenAI Pricing: https://openai.com/pricing
HuggingFace embedding: https://huggingface.co/spaces/mteb/leaderboard
Instructor Large: https://huggingface.co/hkunlp/instructor-large
Hi Ryan, just came across this post and really liked it, will suscribe and read the other interesting looking articles as I'm diving into LLMs and RAG recently.
By the way, unsure if a mistake or not, but in the code section that follows the Hello LangChain title, there's a hard coded API key
I think saying "New York is 278% the size of Houston" is correct?
I could say I have a bag of 10 apples and Ryan has a bag of 5 apples, so my bag is 100% bigger than Ryan's bag. (100% of 5 apples is 5 apples. 5 apples + 5 apples is 10.)