
LlamaIndex: How to use Index correctly.
and understanding what use case for what type of index

Wow, I am absolutely thrilled by the overwhelming response to my first Substack post on building a PDF chatbot! I have received so many messages requesting Part 2, and I cannot express how grateful I am for your interest and enthusiasm, but I think it’s important to take a step back and ensure that we fully understand the Llamaindex before diving into the next phase of building.
I know how easy it is to get caught up in the excitement of creating something new and fancy, but if we don’t have a thorough understanding of the underlying principles, we may quickly forget what we’ve built or encounter issues down the line.
“True mastery comes from understanding the fundamental principles and applying them with creativity and innovation.” — Robert Greene
Rather than rushing into the coding and implementation phase, I believe it’s essential to prioritize a deep understanding of the Llamaindex and the concepts that underpin it. By doing so, we’ll be able to better comprehend how to apply these principles to our specific project and avoid unnecessary errors.
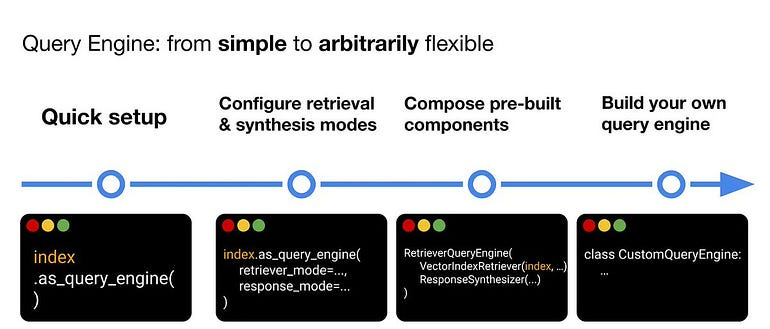
Therefore, I propose that we spend some time delving into the intricacies of the Llamaindex and its significance in chatbot development before proceeding with Part 2. By extending our knowledge and grasping the fundamentals, we’ll be better equipped to create a robust and effective PDF chatbot.
In this post, I’ll cover the essential components of the Llamaindex, its practical applications in chatbot development, and the benefits of taking the time to understand it.
Can I just read the official document?
“Why don’t you focus on building the app instead of explaining something that we can easily read through officials' documents?”
Yes, I totally agree, but in order to access the entire document, it is necessary to visit the official website. It is worth noting that the official website is not always up-to-date and may not provide a detailed explanation of the information. As such, it might be necessary to seek out additional resources or conduct further research to fully understand the content. This can be a time-consuming process, but it is important to ensure that the information obtained is accurate and reliable.
Not only do I provide a detailed explanation but also the real use cases and what scenario to use what index so you will have a better understanding of the foundation of what you are going to build on top of.
A brief introduction to LlamaIndex
LlamaIndex (also known as GPT Index) is a user-friendly interface that connects your external data to Large Language Models (LLMs). It offers a range of tools to streamline the process, including data connectors that can integrate with various existing data sources and formats such as APIs, PDFs, docs, and SQL. Additionally, LlamaIndex provides indices for your structured and unstructured data, which can be effortlessly used with LLMs.
This article will discuss the different types of indexes provided by LlamaIndex and how they can be used. This could include a breakdown of list indexes, vector store indexes, tree indexes, and keyword table indexes, as well as special indexes such as graph indexes, Pandas indexes, SQL indexes, and document summary indexes. Additionally, I will go through the case for each index and it may be worth discussing the cost of using LlamaIndex and comparing it to alternative options.
Why do we need LlamaIndex at all?
Isn’t the commercial ChatGPT good enough?
Yes, it may be sufficient in general use cases, but remember that our goal is to build universal chatbot applications on your lake of documents. Think about the corporate docs you may have with more than 1000 pages, then the ChatGPT commercial won’t be anywhere good enough to analyze your stuff. The main reason is token limits.
GPT-3: about 2000 tokens
GPT-3.5: about 4000 tokens
GPT-4: up to 32.000 tokens
*1,000 tokens is about 750 words

How does LlamaIndex fit in?
If you don’t have many tokens available, you won’t be able to input larger datasets into the prompt, which can limit what you can do with your model. However, you can still train the model, although there are some pros and cons to consider (stay tuned for my upcoming blog post where I’ll compare different solutions). But don’t worry, LlamaIndex is here to help! With LlamaIndex, you can index a variety of data sets like documents, PDFs, and databases, and then easily query them to find the information you need.
Just imagine being able to access all the information you need with just a few clicks! You can ask complex questions directly to your knowledge base, Slack, and other communication tools, as well as databases and virtually any SaaS content you have, without needing to prepare your data in any special way. And the best part? You’ll get answers backed by the reasoning power of GPT, all within seconds, without even having to copy and paste anything into prompts.
By implementing GPT Index properly, you can make all of this possible! In the next section, we will dig into the different types of indexes followed by applicable code ready for your applications.
Indexing with LlamaIndex
Prior to being able to effectively ask questions in natural language and receive accurate answers, it is necessary to index the relevant datasets. As previously stated, LlamaIndex has the capability to index a broad range of data types, and with the upcoming advent of GPT-4, multimodal indexing will soon be available as well. So this part, we will look into the different types of indexes that LlamaIndex offers and see what index use for what use case.
Before we go into the details of the index, you should know that at its core, LlamaIndex breaks your documents into multiple Node objects. Nodes are first-class citizens in LlamaIndex. Nodes represent “chunks” of source Documents, whether that is a text chunk, an image, or more. They also contain metadata and relationship information with other nodes and index structures. When you create the index, it abstracts away the creation of nodes, however, you can manually define nodes for your documents if it is necessary and needed for your requirements.
Let’s set up some ground code first.
Install libraries
pip install llama-index
pip install openaiSetup OpenAI API Key
import os
os.environ['OPENAI_API_KEY'] = '<YOUR_OPENAI_API_KEY>'
import logging
import sys
## showing logs
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
## load the PDF
from langchain.text_splitter import RecursiveCharacterTextSplitter
from llama_index import download_loader
# define loader
UnstructuredReader = download_loader('UnstructuredReader', refresh_cache=True)
loader = UnstructuredReader()
# load the data
documents = loader.load_data('../notebooks/documents/Apple-Financial-Report-Q1-2022.pdf',split_documents=False)List Index
The list index is a simple data structure where nodes are stored in a sequence. The document texts are chunked up, converted to nodes, and stored in a list during index construction.

During query time, if no other query parameters are specified, LlamaIndex simply loads all Nodes in the list into the Response Synthesis module.

The list index does offer numerous ways of querying a list index, from an embedding-based query which will fetch the top-k neighbours, or with the addition of a keyword filter, as seen below:

This list index is useful for synthesizing an answer that combines information across multiple data sources
LlamaIndex provides embedding support to list indices. In addition to each node storing text, each node can optionally store an embedding. During query time, we can use embeddings to do max-similarity retrieval of nodes before calling the LLM to synthesize an answer.
Since similarity lookup using embeddings (e.g. using cosine similarity) does not require an LLM call, embeddings serve as a cheaper lookup mechanism instead of using LLMs to traverse nodes.
It means during index construction, LlamaIndex won’t call LLM to generate embedding but will generate it during query time. This design choice prevents the need to generate embeddings for all text chunks during index construction which may costly with large chunks of data.
As you’ll soon discover, combining multiple indexes together can help you avoid high embedding costs. But that’s not all — it can also improve the overall performance of your application! Another way is to use your custom embedding (instead of using OpenAI), but we won’t look into this method in this article as it deserves another one.
from llama_index import GPTKeywordTableIndex, SimpleDirectoryReader
from IPython.display import Markdown, display
from langchain.chat_models import ChatOpenAI
## by default, LlamaIndex uses text-davinci-003 to synthesise response
# and text-davinci-002 for embedding, we can change to
# gpt-3.5-turbo for Chat model
index = GPTListIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What is net operating income?")
display(Markdown(f"<b>{response}</b>"))
## Check the logs to see the different between th
## if you wish to not build the index during the index construction
# then need to add retriever_mode=embedding to query engine
# query with embed_model specified
query_engine = new_index.as_query_engine(
retriever_mode="embedding",
verbose=True
)
response = query_engine.query("What is net operating income?")
display(Markdown(f"<b>{response}</b>"))
Vector Store Index
It is most common and simple to use, allows answering a query over a large corpus of data

By default, GPTVectorStoreIndex uses an in-memory SimpleVectorStore that’s initialized as part of the default storage context.
Unlike list index, vector-store based indices generate embeddings during index construction
Meaning the LLM endpoint will be called during index construction to generate embeddings data.
Querying a vector store index involves fetching the top-k most similar Nodes, and passing those into our Response Synthesis module.

from llama_index import GPTVectorStoreIndex
index = GPTVectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
responseTree Index
It is useful for summarizing a collection of documents
The tree index is a tree-structured index, where each node is a summary of the children's nodes. During index construction, the tree is constructed in a bottoms-up fashion until we end up with a set of root nodes.
The tree index builds a hierarchical tree from a set of Nodes (which become leaf nodes in this tree).

Querying a tree index involves traversing from root nodes down to leaf nodes. By default, (child_branch_factor=1), a query chooses one child node given a parent node. If child_branch_factor=2, a query chooses two child nodes per level.

Unlike vector index, LlamaIndex won’t call LLM to generate embedding but will generate it during query time. Embeddings are lazily generated and then cached (if retriever_mode="embedding" is specified during query(...)), and not during index construction.
from llama_index import GPTTreeIndex
new_index = GPTTreeIndex.from_documents(documents)
response = query_engine.query("What is net operating income?")
display(Markdown(f"<b>{response}</b>"))
## if you want to have more content from the answer,
# you can add the parameters child_branch_factor
# let's try using branching factor 2
query_engine = new_index.as_query_engine(
child_branch_factor=2
)
response = query_engine.query("What is net operating income?")
display(Markdown(f"<b>{response}</b>"))To build Tree Index during query time, we will need to add retriever_mode and response_mode to the query engine and set the build_tree parameters in the GPTTreeIndex to False
index_light = GPTTreeIndex.from_documents(documents, build_tree=False)
query_engine = index_light.as_query_engine(
retriever_mode="all_leaf",
response_mode='tree_summarize',
)
query_engine.query("What is net operating income?")Keyword Table Index
It is useful for routing queries to the disparate data source
The keyword table index extracts keywords from each Node and builds a mapping from each keyword to the corresponding Nodes of that keyword.

During query time, we extract relevant keywords from the query and match those with pre-extracted Node keywords to fetch the corresponding Nodes. The extracted Nodes are passed to our Response Synthesis module.

Noted that
GPTKeywordTableIndex- use LLM to extract keywords from each document, meaning it do require LLM calls during build time.
However, if you use GPTSimpleKeywordTableIndex which uses a regex keyword extractor to extract keywords from each document, it won’t call LLM during build time
from llama_index import GPTKeywordTableIndex
index = GPTKeywordTableIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What is net operating income?")Composability Graph Index
It is useful for building a knowledge graph
With LlamaIndex, you have the ability to create composite indices by building indices on top of existing ones. This feature empowers you to efficiently index your complete document hierarchy and provide tailored knowledge to GPT.
By leveraging composability, you can define indices at multiple levels, such as lower-level indices for individual documents and higher-level indices for groups of documents. Consider the following example:
you could create a tree index for the text within each document.
generate a list index that covers all of the tree indices for your entire document collection.
Code through a scenario: We will do the following steps to demonstrate the ability of the composability graph index:
Create a Tree Index from multiple documents
Generate summary from Tree Index. As mentioned, Tree Index is useful for summarizing a collection of documents.
Next, we will create a Graph with a list index on top of 3 tree indices. Why? because the list index is suitable for synthesizing an answer that combines information across multiple data sources.
Finally querying the graph.
Implementation:
I will read the 10k report between Q1–2022 vs Q1–2023 of Apple and ask financial questions between two quarters.
## re
years = ['Q1-2023', 'Q2-2023']
UnstructuredReader = download_loader('UnstructuredReader', refresh_cache=True)
loader = UnstructuredReader()
doc_set = {}
all_docs = []
for year in years:
year_docs = loader.load_data(f'../notebooks/documents/Apple-Financial-Report-{year}.pdf', split_documents=False)
for d in year_docs:
d.extra_info = {"quarter": year.split("-")[0],
"year": year.split("-")[1],
"q":year.split("-")[0]}
doc_set[year] = year_docs
all_docs.extend(year_docs)Creating vector indices for each quarter.
## setting up vector indicies for each year
#---
# initialize simple vector indices + global vector index
# this will use OpenAI embedding as default with text-davinci-002
service_context = ServiceContext.from_defaults(chunk_size_limit=512)
index_set = {}
for year in years:
storage_context = StorageContext.from_defaults()
cur_index = GPTVectorStoreIndex.from_documents(
documents=doc_set[year],
service_context=service_context,
storage_context=storage_context
)
index_set[year] = cur_index
# store index in the local env, so you don't need to do it over again
storage_context.persist(f'./storage_index/apple-10k/{year}')Generate summary from Tree Index. As mentioned, Tree Index is useful for summarizing a collection of documents.
# describe summary for each index to help traversal of composed graph
index_summary = [index_set[year].as_query_engine().query("Summary this document in 100 words").response for year in years]Next, we will create a Graph with a list index on top of 3 tree indices
### Composing a Graph to Synthesize Answers
from llama_index.indices.composability import ComposableGraph
from langchain.chat_models import ChatOpenAI
from llama_index import LLMPredictor
# define an LLMPredictor set number of output tokens
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, max_tokens=512, model_name='gpt-3.5-turbo'))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
storage_context = StorageContext.from_defaults()\
## define a list index over the vector indicies
## allow us to synthesize information across each index
graph = ComposableGraph.from_indices(
GPTListIndex,
[index_set[y] for y in years],
index_summaries=index_summary,
service_context=service_context,
storage_context=storage_context
)
root_id = graph.root_id
#save to disk
storage_context.persist(f'./storage_index/apple-10k/root')
## querying graph
custom_query_engines = {
index_set[year].index_id: index_set[year].as_query_engine() for year in years
}
query_engine = graph.as_query_engine(
custom_query_engines=custom_query_engines
)
response = query_engine.query("Outline the financial statement of Q2 2023")
response.responseWant to know how we can leverage Langchain Agent for a Chatbot, follow/subscribe for more update in the future :)
Pandas Index and SQL Index
It is useful for structured data
Simple and very straightforward, I will go straight into the demo.
Pandas Index:
from llama_index.indices.struct_store import GPTPandasIndex
import pandas as pd
df = pd.read_csv("titanic_train.csv")
index = GPTPandasIndex(df=df)
query_engine = index.as_query_engine(
verbose=True
)
response = query_engine.query(
"What is the correlation between survival and age?",
)
response
SQL Index:
Think about a cool application where you can attach your LLM app to your database and ask questions on top of it. This sample code taken from here
# install wikipedia python package
!pip install wikipedia
from llama_index import SimpleDirectoryReader, WikipediaReader
from sqlalchemy import create_engine, MetaData, Table, Column, String, Integer, select, column
wiki_docs = WikipediaReader().load_data(pages=['Toronto', 'Berlin', 'Tokyo'])
engine = create_engine("sqlite:///:memory:")
metadata_obj = MetaData()
# create city SQL table
table_name = "city_stats"
city_stats_table = Table(
table_name,
metadata_obj,
Column("city_name", String(16), primary_key=True),
Column("population", Integer),
Column("country", String(16), nullable=False),
)
metadata_obj.create_all(engine)
from llama_index import GPTSQLStructStoreIndex, SQLDatabase, ServiceContext
from langchain import OpenAI
from llama_index import LLMPredictor
llm_predictor = LLMPredictor(llm=LLMPredictor(llm=ChatOpenAI(temperature=0, max_tokens=512, model_name='gpt-3.5-turbo')))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
sql_database = SQLDatabase(engine, include_tables=["city_stats"])
sql_database.table_info
# NOTE: the table_name specified here is the table that you
# want to extract into from unstructured documents.
index = GPTSQLStructStoreIndex.from_documents(
wiki_docs,
sql_database=sql_database,
table_name="city_stats",
service_context=service_context
)
# view current table to verify the answer later
stmt = select(
city_stats_table.c["city_name", "population", "country"]
).select_from(city_stats_table)
with engine.connect() as connection:
results = connection.execute(stmt).fetchall()
print(results)
query_engine = index.as_query_engine(
query_mode="nl"
)
response = query_engine.query("Which city has the highest population?")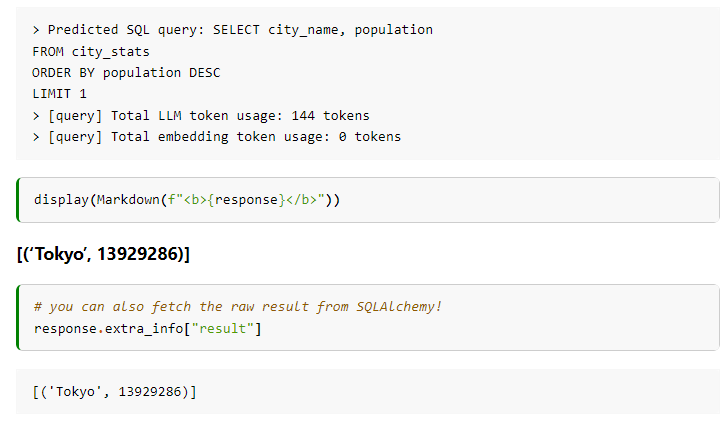
Under the hood, there is a Langchain library plug-in to play. We will cover Langchain in another post.
Document Summary Index
This is a brand new LlamaIndex data structure and it is kinda made with the purpose of question-answering. So far, we have gone through the individual index and for sure we can build our LLM QA app with it either by using a single index or combining multiple indexes together.
Commonly, LLM-powered QA systems are developed in the following manner by most users:
They take source documents and divide them into text chunks.
The text chunks are then stored in a vector database.
During query time, the text chunks are retrieved by utilizing similarity and/or keyword filters for embedding.
Response synthesis is performed.
However, this approach has several limitations that impact retrieval performance.
Drawbacks of Current Methods:
Text chunks do not have a complete global context, and this often limits the effectiveness of the question-answering process.
There is a need for careful tuning of top-k / similarity score thresholds, as a value that is too small could result in the relevant context being missed, whereas a value that is too large can increase cost and latency with irrelevant context.
Embeddings may not always select the most appropriate context for a question, as the process inherently determines text and context separately.
To enhance retrieval results, some developers add keyword filters. However, this approach has its own set of challenges, such as identifying the appropriate keywords for each document either through manual efforts or by using an NLP keyword extraction/topic tagging model, as well as inferring the correct keywords from the query.

That is where LlamaIndex introduces Document Summary Index which can extract and index an unstructured text summary for each document, which enhances retrieval performance beyond existing approaches. This index contains more information than a single text chunk and carries more semantic meaning than keyword tags. It also allows for flexible retrieval, including both LLM and embedding-based approaches.
During build-time, this index ingests document and use LLM to extract a summary from each document. During query time, it retrieves relevant documents to query based on summaries using the following approaches:
LLM-based Retrieval: get collections of document summaries and request LLM to identify the relevant documents + relevance score
Embedding-based Retrieval: utilize summary embedding similarity to retrieve relevant documents, and impose a top-k limit to the number of retrieved results.
Noted: The retrieval classes for the document summary index retrieve all nodes for any selected document, instead of returning relevant chunks at the node-level.
Let’s get into the example:
import nest_asyncio
nest_asyncio.apply()
from llama_index import (
SimpleDirectoryReader,
LLMPredictor,
ServiceContext,
ResponseSynthesizer
)
from llama_index.indices.document_summary import GPTDocumentSummaryIndex
from langchain.chat_models import ChatOpenAI
wiki_titles = ["Toronto", "Seattle", "Chicago", "Boston", "Houston"]
from pathlib import Path
import requests
for title in wiki_titles:
response = requests.get(
'https://en.wikipedia.org/w/api.php',
params={
'action': 'query',
'format': 'json',
'titles': title,
'prop': 'extracts',
# 'exintro': True,
'explaintext': True,
}
).json()
page = next(iter(response['query']['pages'].values()))
wiki_text = page['extract']
data_path = Path('data')
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", 'w') as fp:
fp.write(wiki_text)
# Load all wiki documents
city_docs = []
for wiki_title in wiki_titles:
docs = SimpleDirectoryReader(input_files=[f"data/{wiki_title}.txt"]).load_data()
docs[0].doc_id = wiki_title
city_docs.extend(docs)
# # LLM Predictor (gpt-3.5-turbo)
llm_predictor_chatgpt = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor_chatgpt, chunk_size_limit=1024)
# default mode of building the index
response_synthesizer = ResponseSynthesizer.from_args(response_mode="tree_summarize", use_async=True)
doc_summary_index = GPTDocumentSummaryIndex.from_documents(
city_docs,
service_context=service_context,
response_synthesizer=response_synthesizer
)
doc_summary_index.get_document_summary("Boston")Knowledge Graph Index
It builds the index by extracting knowledge triples in the form (subject, predicate, object) over a set of docs.
During the query time, it can either query using just the knowledge graph as context or leverage the underlying text from each entity as context. By leveraging the underlying text, we can ask more complicated queries with respect to the contents of the document.
Think about a graph as like, well graph, where you can see all the edges and vertexes that are interconnected.

You can have a look at this page for your reference.
Fact to consider
During the implementation of LLMs for our PDF Chatbots, I drew attention to important aspects that we want to share with you, namely: indexation cost, and indexation time (speed).
Indexing Cost
The expense of indexing is a crucial factor to consider, as I highlighted earlier in this article. This is particularly significant when dealing with massive datasets, which is why I advocate the use of LlamaIndex.
You can find prices for individual OpenAI models.
Indexing Speed
The second important issue is the time of document indexing, i.e. preparing the entire solution for operation. According to my experiment, the indexation time varies but it is a one-off and also depends on the OpenAI server.
Usually, the pdf with 40 pages will take approximately 5 seconds. Imagine a huge dataset with more than 100k pages, it could take to several days. We can leverage the async method to reduce the indexing time. I will write about this in another post.
Summary

As always, I will cover and write more about building LLM Apps. So follow/subscribe for more. And if this article helps you somehow, please give me a clap and please leave a comment if you have any questions.
List and References:
Reach out to me on my LinkedIn
Email if you need: howaibuiltthis@gmail.com
Thanks for your post. It's very detail :D