
Zero to One: A Guide to Building a First PDF Chatbot with LangChain & LlamaIndex - Part 1
Two main frameworks to build anything with large language models in Python

Welcome to Part 1 of our engineering series on building a PDF chatbot with LangChain and LlamaIndex. Don't worry, you don't need to be a mad scientist or a big bank account to build and train a model. With the rise of Large Language Models (LLMs) such as ChatGPT and GPT-3, it's now easier than ever to build intelligent chatbots that are smarter than your average bear and can go through mountains of your documents to provide accurate responses to your inputs.

In this series, we will be exploring how to use pre-trained LLMs to create a chatbot that can analyze and summarize and do question-answering on PDF documents, making it an incredibly useful tool for businesses and individuals alike. Whether you want to build a personal assistant, a customized chatbot, or an automated document analysis system, this series will provide you with the knowledge you need to take your first steps towards building your own LLM-powered chatbot. So, let's dive into the world of LLMs and chatbots with LangChain and LlamaIndex!
What we will build
The idea of using ChatGPT as an assistant to help synthesize documents and provide a question-answering summary of documents are quite cool. At first, the idea was to fine-tune the model with specific data to achieve this goal, but it can be costly and requires a large dataset. Additionally, fine-tuning the model can only teach it a new skill rather than provide complete information about the documents.
Another approach is to use prompt engineering to provide the context in the prompts for (multi-)document QA. However, the GPT model has a limited attention span, and passing along context to the API can also be expensive, especially when dealing with a large number of customer feedback emails and product documents.
So how are we building it?
Following are steps on how we accomplish such those things:
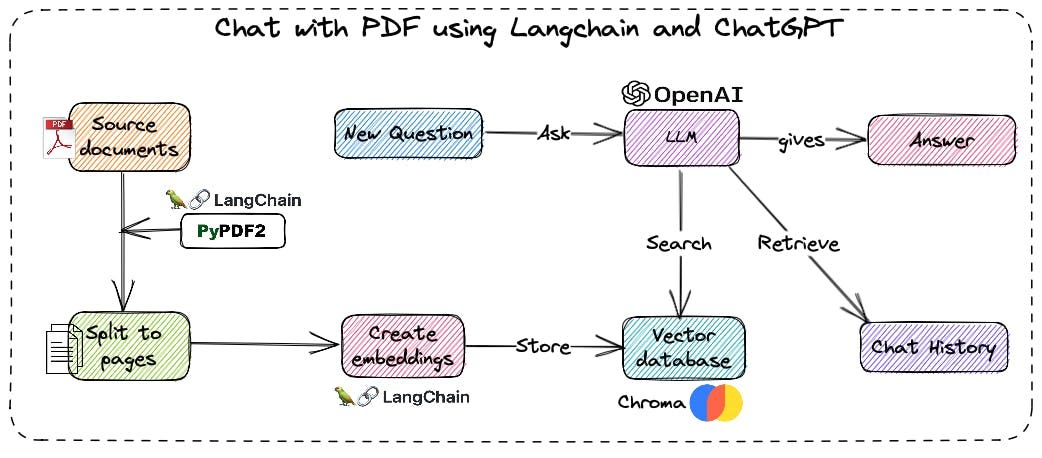
We first load the document (PDF, HTML, text, Database, etc)
We then split data into chunks, create embedding on top of data to represent data in some form of the number and do indexes on top of embedding data. This way we can do a semantic search based on all the popular algorithms.
For each question, we will search through indexes and embedding data to extract the relevant information only.
Pass through questions and relevant data into LLM Model. We will use Open AI in this series.
It sounds too complex and it is indeed. That is where Langchain and LLamaIndex come to the rescue. The only difficult thing here is to get yourself familiar with that two frameworks. The rocket science of indexes and embedding and LLM stuff will be taken care of by those frameworks :)
How do we start
Yet the road to enlightenment is not an easy one, and many challenges lie ahead for those. I have had a hard time understanding all the concepts and put a lot of practice to get myself familiar with building LLM applications. There are no series and end-to-end tutorials out there and all you have is official documents, and trust me, you must go through the document if you want to be proficient. However, the official document is quite hard and sometimes short and not updated. You may find a very very very very hard time understanding all the concepts with a lot of hectic what and why questions. It will be challenging if you don’t have a background in data science or machine learning, etc. But don’t worry, I aim to explain all of those in this series.
This series intend to give you not only a quick start of learning about the framework but also to arm you with tools, and techniques outside Langchain and LLamaIndex to incorporate into your app and even go further to bring your apps to production.
I won’t go into detail about Langchain or LLamaIndex in this part 1 but rather keep it in a separate post. This Part 1 is all about building, to give you the taste you like first before showing you the recipe and ingredients.
Our menu will serve the following meals:
Generative Question-Answering with Langchain
Generative Question-Answering with LLamaIndex
Bonus section.
Let’s start shall we?
Housekeeper
To follow along in this tutorial, you will need to have the OpenAI API keys and Python packages.
To get OpenAI API keys, you can follow this article here
In short, go to https://platform.openai.com, log in or signup for a new account → Click to your profile → View API Keys
and create a new secret key

Remember to setup usage limit to not break your bank (hard lesson learnt)

Alternatively, we can use other LLM providers but for this blog, we will use OpenAI. I will give your more content and ideas on how to integrate with different LLM providers as well as pros and cons for each (subscribe guyssss)
Assuming you already have Python in your machine, we will need python >= 3.7 to work on, the NExt step is to create a virtual environment and install the following Python library:
## to create virtual environment
$ python3 -m venv llm_app_env
## on MacOS or Linux
$ source llm_app_env/bin/activate
## on Window
$ llm_app_env\Scripts\activate.bat
## then install the following libraries.
openai[embeddings]==0.27.6
langchain==0.0.155
pypdf==3.8.1
tiktoken==0.3.3
faiss-cpu==1.7.4
unstructured==0.6.2
chromadb==0.3.21
llama-index==0.6.1
jupyterlabLangchain Starter
LangChain is a powerful open-source tool that makes it easy to interact with large language models and build applications. Think about it as a middleman to connect your application to a wide range of LLM Providers like OpenAI, Cohere, Huggingface, Azure OpenAI and more.
But LangChain isn't just a tool for accessing pre-trained language models. It also provides a number of useful features and functionalities that allow you to build custom applications and tools. For example:
Questions-answering and text summarization with your own documents
Deal with memory and long documents with limited token issues.
Awesome integration with OpenAI ChatGPT Retriever Plugin
Multiple chains to work on your defined problems or take it higher with Agents.
And many more.
At a high level, Langchain is a great framework that makes the power of the creation of AI applications now in your hand. More amazingly, it is open-source so you know it is in the good hand of brilliant communities. I won’t go too deep into LangChain and its component, you can find more about Langchain on their website or subscribe to my substack to get the deep dive development of Langchain in the future.
As the main purpose of this blog is to keep things simple and go straight into development, let's fire up your jupyter notebook and start coding.
Setup OpenAI API KEY
import logging
import sys
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"Load and split the data
## load the PDF using pypdf
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# load the data
loader = PyPDFLoader('../notebooks/documents/Apple-Financial-Report-Q1-2022.pdf')
# the 10k financial report are huge, we will need to split the doc into multiple chunk.
# This text splitter is the recommended one for generic text. It is parameterized by a list of characters.
# It tries to split on them in order until the chunks are small enough.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
data = loader.load()
texts = text_splitter.split_documents(data)
# view the first chunk
texts[0]Simple Question Answering
Now I know we are going to use OpenAI as LLM Provider so it makes total sense that we should go with OpenAI Embedding. But please note that the OpenAI Embedding API use “text-davinci-003” model, you can view the pricing here, it may cost less for a small document but be careful when you intend to apply for a big chunk of documents (don’t break your bank guys).
NExt steps, we will import the Chroma. If you are not familiar with Chroma, then you can find the detail on its official website. Again, I will cover Chroma and its alternative sometime in the future. So the question is, what is Chroma and why do we need it?
In short, Chroma is the embedding database, not like the traditional SQL database or the not-too-new NoSQL database like what you usually work with. It is embedding databases and it makes it easy to build LLM apps.

Our document is represented in the form of text which makes it challenging to find relevant info based on the question. Say you need to find the revenue of Apple in the last quarter in 1000 pages and compare revenue to previous years. How challenging and time-consuming it may take? So to make our search easier, we will first need to transform or represent words or phrases in a numerical format that can be used as input to machine learning models. In other words, to help machines understand the text. An embedding maps each word or phrase to a vector of real numbers, typically with hundreds of dimensions, such that similar words or phrases are mapped to similar vectors in the embedding space.
One of the main advantages of using embeddings is that they can capture the semantic and syntactic relationships between words or phrases. For example, in an embedding space, the vectors for "king" and "queen" would be closer to each other than to the vector for "apple", because they are semantically related as royal titles.

So, the embedding database does exactly that. It will store all the embedding data in the database and then give us very indexes to allow us to perform an action like data retrieval and do it in a scalable style. If you need to get the answer to the previous question of finding revenue of Apple last quarter, we will first need to perform a similarity search or semantic search on top of embedding a database like Chroma to extract relevant information and feed that information to LLM model to get the answer.
Sounds too complex !! that is where Langchain comes to the rescue with all the hard work will be done in the background for us. Let’s start coding, shall we?
# import Chroma and OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
# initialize OpenAIEmbedding
embeddings = OpenAIEmbeddings(model='text-embedding-ada-002')
# use Chroma to create in-memory embedding database from the doc
docsearch = Chroma.from_documents(texts, embeddings, metadatas=[{"source": str(i)} for i in range(len(texts))])
## perform search based on the question
query = "What is the operating income?"
docs = docsearch.similarity_search(query)You see we are able to perform a similarity search to get relevant information from the embedding database.
Now, we will use one of the main components of Langchain which is Chain to incorporate LLM provider into our code. Again, I know it is hard to digest all of the concepts at once but hey, I will cover all of them in another post. Remember, the purpose of this guide is to build the question-answering bot. So just follow the step and if you are curious and can’t wait to dig more into details, feel free to go to Langchain's official website. Valhalla awaits!!!!

There are four types of pre-built question-answering chains:
Question Answering: load_qa_chain
Question Answering with Sources: load_qa_with_sources_chain
Retrieval Question Answer: RetrievalQA
Retrieval Question Answering with Sources: RetrievalQAWithSourcesChain
They are pretty much similar, under the hood, RetrievalQA and RetrievalQAWithSourcesChain use load_qa_chain and load_qa_with_sources_chain respectively, the only difference is the first two will take all the embedding to feed into LLM while the last two only feed LLM with relevant information. We can use the first two to extract the relevant information first and feed that info to LLM only. Also, the first two give us more flexibility than the last two.
The following piece of code will demonstrate how we do it.
## importing necessary framework
from langchain.chains.question_answering import load_qa_chain
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.chains import RetrievalQA
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.chat_models import ChatOpenAINow we will try 4 different question-answering chains
1. load_qa_chain
## use LLM to get answering
chain = load_qa_chain(ChatOpenAI(temperature=0.2,model_name='gpt-3.5-turbo'),
chain_type="stuff")
query = "What is the operating income?"
chain.run(input_documents=docs, question=query)2. load_qa_with_sources_chain
chain = load_qa_with_sources_chain(ChatOpenAI(temperature=0.2,model_name='gpt-3.5-turbo'),
chain_type="stuff")
query = "What is the operating income?"
chain({"input_documents": docs, "question": query}, return_only_outputs=True)3. RetrievalQA
qa=RetrievalQA.from_chain_type(llm=ChatOpenAI(temperature=0.2,model_name='gpt-3.5-turbo'), chain_type="stuff",
retriever=docsearch.as_retriever())
query = "What is the operating income?"
qa.run(query)4. RetrievalQAWithSourcesChain
chain=RetrievalQAWithSourcesChain.from_chain_type(ChatOpenAI(temperature=0.2,model_name='gpt-3.5-turbo'), chain_type="stuff",
retriever=docsearch.as_retriever())
chain({"question": "What is the operating income?"}, return_only_outputs=True)Pretty easy ayy. Most of the code above is pretty basic. We just want to get this work done before digging into more depth about what does framework can offer. Until then, let’s move on to another framework that you can use in conjunction with Langchain and it will give you more power to create even better LLM apps.
LLamaIndex Starter
I think we can both agree on this. I hate the name “LLamaIndex”, it is too confusing and too hard to pronounce. To this day, I don’t think I can pronounce LLamaIndex correctly, that is why I prefer to call it GPT-Index even though the author has published a reason why they change the name.
Anyway, to the main story.
I started off by introducing Langchain and if you spent some time going over its official document, you may have thought “Woaaa, no good can come above this”.
Well, my friends, there is an entire SaaS industry that builds on top of AWS just to make you a better and easy way to use AWS services. Same for the races between other LLM frameworks or LLM models. We are living in a world where something that is good today may be obsolete tomorrow. I personally think Langchain will have a very bright future and will be the central piece of tech that is used to build LLM apps. LLamIndex even makes our job easier and it also introduces its own edges by handling some painful well know issues and limitations of existing approaches that will take you time and manual stuff to work on such as:
Text chunks lack global context. Oftentimes the question requires context beyond what is indexed in a specific chunk.
Careful tuning of top-k / similarity score thresholds. Make the value too small and you’ll miss context. Make the value too big and cost/latency might increase with more irrelevant context.
Embeddings don’t always select the most relevant context for a question. Embeddings are inherently determined separately between text and the context.
LLamaIndex (GPT-Index) has its own mechanism to handle those limitations. Again, the purpose of this blog is to get the job done. I won’t go into detail on how LLamaIndex works. You can always find it on the official documents. However, I will go deep into LLamaIndex in future newsletters.
So What is LLM
Verily, not but a short time passed, did I come across a parchment scribed by Jerry Liu, wherein he did unveil the LlamaIndex, a portal that harnesses the power of GPT to fashion rejoinders to inquiries by making use of knowledge proffered by the inquirer.
In short, LlamaIndex is another way (similar to Langchain’s way) to respond to queries by connecting LLMs to the users by following these steps:
Load in documents (either manually, or through a data loader)
Parse the Documents into Nodes
Construct Index (from Nodes or Documents)
[Optional, Advanced] Building indices on top of other indices
Query the index
In simple terms, LlamaIndex loads your data into a document object and converts it into an index. When you input a query, the index sends it to a GPT prompt to generate a response, using OpenAI's text-davinci-003 model by default. Despite the seemingly complex process, it can be executed with just a few lines of code, as you will soon learn.

You will soon see how easy it is to use LLamaIndex since it has done all the hard work under the hood. Your job is simply reading through its official document, learning different type of index, and then analysing your app requirements to see what suit you the most. Of course, there will be more and more complex kinds of stuff you may need in your app and the high-level API of LLamaIndex may not be enough to handle such cases. That is where you find how convenient it is that LLamaIndex can integrate with other tools like Langchain to make your development process faster.
Let’s start by setting up the simple index and loading the document.
import logging
import sys
## setup your OpenAI Key
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
# enable logs to see what happen underneath
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))The centrepiece of LlamaIndex is, well, the index and there are multiple types of index.
List Index
Vector Store Index
Tree Index
Keyword Table Index
Graph Index
SQL Index.
Each index has it own unique usage with different purposes. The good thing is you can stack index on top of other indexes, doing so will give your app more powerful to understand your document context and app requirements.
The first step is to load documents
from llama_index import GPTVectorStoreIndex
from llama_index import download_loader
# we will use this UnstructuredReader to read PDF file
UnstructuredReader = download_loader('UnstructuredReader', refresh_cache=True)
loader = UnstructuredReader()
# load the data
data = loader.load_data(f'../notebooks/documents/_10-Q-Q1-2022-(As-Filed).pdf', split_documents=False)A Document represents a lightweight container around the data source. You can now choose to proceed with one of the following steps:
Feed the Document object directly into the index
First, convert the Document into Node objects
Again, the purpose of this series is to help you build the first app as quickly as possible, so I will go straight to index construction. I will cover all the aspects of LLamaIndex in a future post.
Index Construction and Query
We can now build an index over these Document objects. The simplest high-level abstraction is to load the Document objects during index initialization.
index = GPTVectorStoreIndex.from_documents(data)
query_engine = index.as_query_engine()
response = query_engine.query("What is the operating income?")
print(response)
How cool is this ay !!!
Depending on which index you use, LlamaIndex may make LLM calls in order to build the index. GPTVectorStoreIndex won’t call LLM but GPTTreeStoreIndex will.
Customizing LLM’s
By default, LlamaIndex uses OpenAI’s text-davinci-003 model. You may choose to use another LLM when constructing an index.
from llama_index import LLMPredictor, PromptHelper, ServiceContext
from langchain.chat_models import ChatOpenAI
# define LLM
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0.2,model_name='gpt-3.5-turbo'))
# define prompt helper
# set maximum input size
max_input_size = 4096
# set number of output tokens
num_output = 256
# set maximum chunk overlap
max_chunk_overlap = 20
prompt_helper = PromptHelper(max_input_size, num_output, max_chunk_overlap)
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper)
index = GPTVectorStoreIndex.from_documents(
documents,
service_context=service_context
)
query_engine = index.as_query_engine()
response = query_engine.query("What is the operating income?")
print(response)That is it guys, you see, in only a few lines of code, we were able to build an LLM app that can do basic question-answering.
For someone who has a background in machine learning engineer or data science, this is fairly easy and straightforward forward but I believe for some people who are new will find it quite confusing sometimes. I understand that but it is super hard to explain everything in one post. The purpose of this post is just to give you a taste of how easy it is nowadays to build such a mind-blowing LLM application. You may have a lot of questions now and may don’t even understand a few lines of code there but it is okay.

“The journey of a thousand miles begins with one step” Lao Tzu
you will soon gather all the pieces of knowledge and aspects of components to build your own LLM applications. You can wait till my next post as I will cover the LlamaIndex in the next one or if you are curious enough then please go ahead to prepare yourself by reading through official documents.
Until then, I wish this article has been helpful in expanding your coding knowledge and providing valuable insights into LLM. Remember to stay curious and continue exploring the vast world of AI.
If you find this post and this series may help you, please subscribe/follow and share my newsletter to stay up to date with the latest articles in this series and other exciting LLM content.
Thank you for reading and I look forward to seeing you in the next newsletter!
BONUSSSSSSSSSSSSS
Congratulations on making it this far! As a reward for your effort, here's a piece of code that you can use to chat with your document
# do imports
from langchain.agents import Tool
from langchain.chains.conversation.memory import ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.agents import initialize_agent
from llama_index.langchain_helpers.agents import LlamaToolkit, create_llama_chat_agent, IndexToolConfig
query_engine = index.as_query_engine()
tool_config = IndexToolConfig(
query_engine=query_engine,
name=f"Financial Report",
description=f"useful for when you want to answer queries about the Apple financial report",
tool_kwargs={"return_direct": True}
)
toolkit = LlamaToolkit(
index_configs=[tool_config]
)
memory = ConversationBufferMemory(memory_key="chat_history")
llm=ChatOpenAI(temperature=0.2,model_name='gpt-3.5-turbo')
agent_chain = create_llama_chat_agent(
toolkit,
llm,
memory=memory,
verbose=True
)
while True:
text_input = input("User: ")
response = agent_chain.run(input=text_input)
print(f'Agent: {response}')And the result
Links and references:
LangChain docs : https://langchain.readthedocs.io/en/latest/index.html
LangChain Prompt Memory module: https://langchain.readthedocs.io/en/latest/modules/memory.html#memory
LangChain Repo : https://github.com/hwchase17/langchain
LlamaIndex docs: https://gpt-index.readthedocs.io/en/latest/index.html
My LinkedIn: https://www.linkedin.com/in/ryan-nguyen-abb844a4
My Medium: https://medium.com/@ryanntk
Great post! Wonder if you ever have posted the next parts?