
LlamaIndex: How to evaluate your RAG applications
Classic 10k reports with Australian real estate market reports just to demonstrate the end-to-end evaluation process

If you’ve followed all of my previous articles or spent some time on the internet, I’m sure that you will find that it is super easy to build an LLM application. From PoC to production-ready, even no-code, low-code solutions can help to integrate the LLM app with the backend and automate most of the boring stuff such as sending emails or triggering the downstream jobs.

However, the big question that lies in the table here is how you can ensure that your app is not answering with made-up facts and unknown material, or in jargon terms hallucinations.
In this article, we are going to explore how to evaluate your LLM app with an end-to-end process with LlamaIndex.
First: Why do we want to evaluate RAG?
To make sure that the response from RAG is producing high-quality content.
Just like the scenario unit test in software engineering, we want to know where we can improve to have a better response.
Performance vs. speed is the trade-off between a faster response vs. a slow response but higher quality.
Compare different approaches to indexing documents and LLM models
We can not just sit down, write some code and kaboom — here is your LLM app. We must evaluate the pipeline to make sure the content generated satisfies us and if not then identifying the area can be improved.
LlamaIndex already has fascinating posts on official documents with different evaluating/observing tools. I will leave more links in the references. In this post, I want to dig into the fundamentals of evaluating processes and creating our own. Having access to those tools is great and very helpful to fasten the evaluation process, however, as the old ones say:
You can get the job done with the tools and you can go anywhere, do anything with the fundamentals.
Personal reason: As the primary consultant/engineer for firms developing chatbots, I’m now researching strategies to consistently improve the effectiveness of data-supported chatbots. I’m working to improve the performance of a single application, the corporate chatdoc, in order to identify solutions that could be more broadly applicable.
Stages of the RAG pipeline
RAG (Retrieval Augmented Generation) is a database-based application that you create. Its main objective is to broaden your understanding of the LLM model. As you are aware, there is always a cut-off knowledge of the LLM model; you can either fine-tune your LLM in your existing database or you may utilize the LLM and have it scan through your database to find the answer to your query (RAG). Each method has advantages and disadvantages, and each merits its own article. Within the scope of this piece, I shall just cover the RAG.
There are few opinions out there but from my point of view, there are 3 main stages of the RAG pipeline.
Indexing Stage: this is the very first step where you need to prepare the knowledge base of your database (embedding data and storing this embedding data)
Querying Stage: scanning and retrieving relevant context from your knowledge based on the different algorithms and passing the returned embedding data to the next stage
Response Stage: or synthesizer stage, with the data retrieval from the querying stage, the LLM will synthesize the answer and respond back to the question

Strategy to Evaluate RAG
When you’re in the process of developing your LLM application, it can be advantageous to begin by establishing a comprehensive evaluation workflow from start to finish. As you progress and begin to gather instances of failures or identify corner cases, along with gaining insights into what is or isn’t performing well, you can then delve more deeply into the assessment and enhancement of specific components.
Consider it in terms of integration tests and unit tests in terms of software testing. As you begin fine-tuning individual pieces, you should probably start writing unit tests. Similarly, your criterion for measuring overall system effectiveness will be based on integration tests. In the evaluation, both sorts of testing are equally important.
End-to-End Assessment
Evaluation at the Component Level
How to choose between those two? well, if you want to get a sense of how your system is performing while you iterate on it, basing your primary development loop around the end-to-end assessment eval makes sense as an overall sanity/vibe check.
The pipeline app has three steps, and using end-to-end assessment will provide you with a quick summary of which stage you should focus on to increase performance.
If you have a concept of what you’re doing and want to iterate on each component one by one, building it up as you go, you might want to start with a component-wise eval. However, there is a risk of early optimization if model selection or parameter selections are made without first analyzing the overall application demands. You may need to go over these options again when creating your final application.
In the scope of this article, I only introduce End-to-End Assessment, the details of Evaluation at the Component Level will come in a separated post
What are the metrics for evaluation?
Machine learning engineers and data scientists are not strange with the evaluation metrics, there are plenty such as Mean Absolute Error (MAE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), R² (R-Squared), etc.
In general, to evaluate the RAG performance, we want to use a Quantitative approach for evaluation. When evaluating applications where there is a correct answer, such as validating that the choice of tools and their inputs are correct given the plan, retrieving specific pieces of information, or attempting to produce an intermediate output of a certain schema (e.g. JSON fields), quantitative eval is more useful.
When generating long-form comments that are meant to be helpful but are not always totally correct, qualitative evaluation is more useful.
There is a range of evaluation options available, including measurements, less expensive models, more expensive models (GPT4), and human evaluation.
Also, using GPT-4 for assessment might be costly, especially if you have a lot of long documents. Metrics ensembling uses an ensemble of weaker signals (exact match, F1, ROUGE, BLEU, BERT-NLI, and BERT-similarity) to forecast the result of more expensive assessment methods (human-labeled/GPT-4).
It is intended to serve two functions:
During the development stage, it is cheap and fast across a huge dataset.
During the production monitoring stage, outliers are flagged for additional evaluation (GPT-4 / human alerting).
Components of the Evaluation Process
Simply think of Evaluation as a unit test with different scenarios/test cases.
Let’s see what are the key concepts of evaluation.
Dataset or Question Generation
We can’t evaluate anything without a dataset. The dataset is a collection of questions that can be used to evaluate the response. Using QuestionGeneration, we can essentially have LLM whip up a bunch of questions to evaluate our RAG pipelines. We’ll let LLM do its magic, generating questions from our documents, and then we can randomly pick some of those questions to serve as our core evaluation queries. Also, we can add or modify the questions manually to create our “golden” set. This way, we can consistently assess how our RAG pipelines are doing, even as we tinker with them.
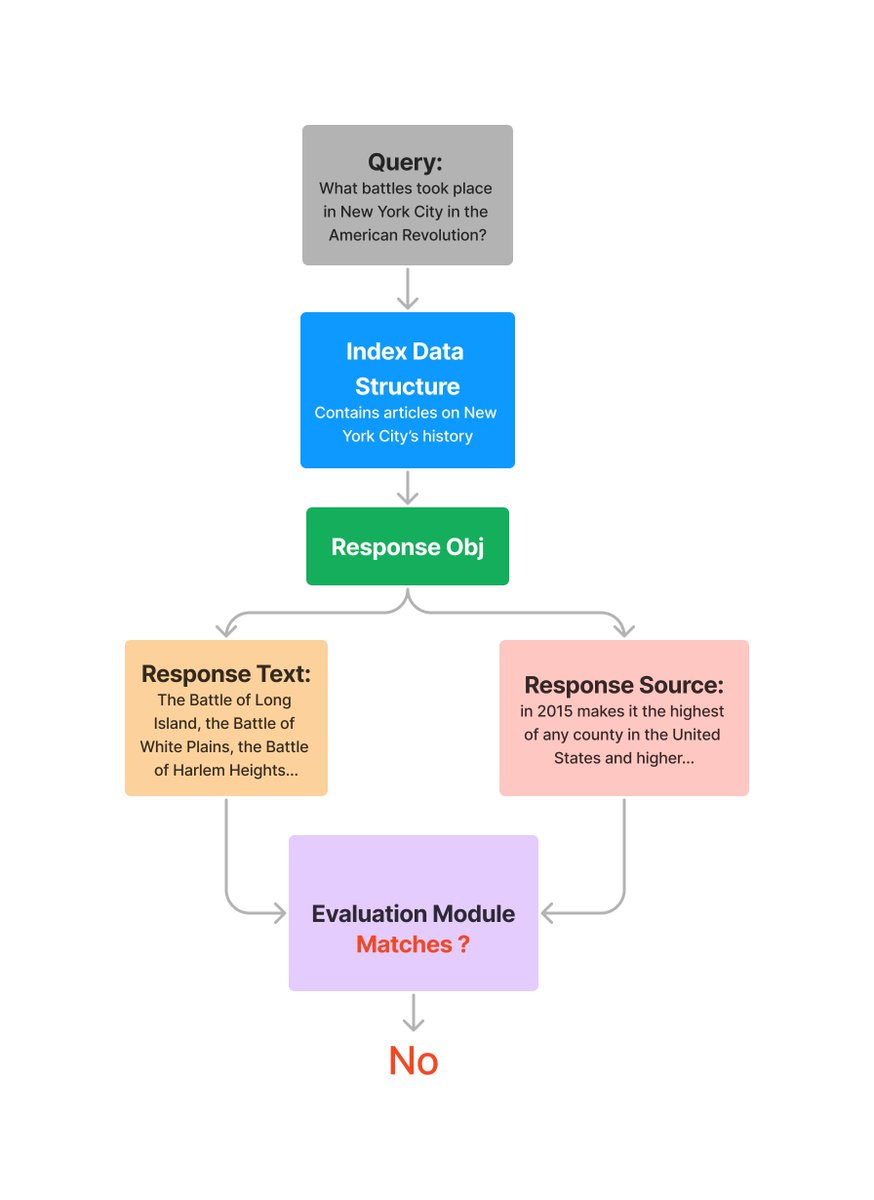
Evaluation of the Response + Context
Serves as a critical component for quantifying the correspondence between the output generated by a query engine and the available response nodes. This functionality proves to be instrumental in the evaluation of potential instances of hallucination within the response data.
Evaluation of the Query + Response + Source Context
is employed to quantify the alignment between the response and the source nodes concerning a given query. This capability is highly valuable in assessing the extent to which the response effectively addresses the query in question.
Show time
Enough talking, we will now start doing implementation details of our very own evaluation of the RAG application.
Just a head up. I hope you’ve read my previous article. I explained all the concepts of building an LLM app with LlamaIndex. If you find it hard to follow or understand the code I put in this section, please refer back to my previous posts on how to build the first chatbot and the basics of LlamIndex with how to use index and how to use storage or spend some time with LlamaIndex’s official document.
Choosing the Right Embedding Model: A Guide for LLM Applications

So you may think that I’m gonna write part 2 of the series on how to build a great chatbot app that is different from 99% of tutorials on the internet. Guess what, it is not gonna happen in this post. I’m sorry in advance but there is a reason why I’m not rushing into part 2 yet and I shall explain to you.
As always, if you have any question, just leave a comment below and I will try to response as soon as possible
Overview of steps:
Step 1: Generate the question dataset — We will use GPT4 to generate the question based on the documents.
Step 2: Evaluating Sample Response
Step 3: Evaluating Faithfulness
Step 4: Evaluating the quality of the answer
Configuration details:
Embedding Model: bge-base-en-v1.5
LLM Model to generate question: GPT4
LLM Model for answering the query: GPT3.5
LLM Model to evaluate: GPT4.
Naive Approach: Use VectorIndex only for indexing data
In the first experiment, we are going to use just VectorIndex for indexing data. We then evaluate the response with this approach, later on, we will use summary + recursive document for data indexing and compare the evaluation between the two approaches.
Note: we will use bge-base-en-v1.5 for embedding the data. If you want to know how to deploy any hugging face model in production, you can find my previous post here and here
AWS SageMaker real-time endpoints with HuggingFace Embedding Models: A Guide for LLM Application

I’m not entirely sure if I should officially label this as “part 2” of the series building a Chatbot app that’s totally unique compared to 99% of the tutorials out there on the internet and is production-ready. The content we’ll cover here sets the groundwork for the rest of our Chatbot journey. Even though I haven’t explicitly labelled it as “part 2,” I…
As you can see, we will use GPT4 latest version for generating and evaluating the response from GTP3.5 previous version. In the scope of this post, we only compare the performance between different indexing, you can replicate a similar method to compare the performance between different LLM models.
Step 1: Generate the question dataset
We will first load the two financial documents: as I’ve worked in fintech before, the financial stuff and how to apply technology to understand and a little farfetched to generate predictions always intrigues me.
We use gpt4 to automatically generate questions dataset. You don’t need to use all the questions generated, just pick 20~30 of them and store them in a txt file. We can reuse those questions to evaluate our RAG pipeline with different approaches to indexing documents such as VectorIndex or Summary + Recursive Document Agent as well as different LLM models.
indexid = 'finance_index'
index_path = 'gdrive/MyDrive/llm-doc/index'
try:
## load index from storage
print(f"Load {indexid} from local path")
storage_context = StorageContext.from_defaults(vector_store=vector_store,
persist_dir=index_path)
index = load_index_from_storage(storage_context=storage_context, index_id=indexid)
except Exception as e:
print(str(e))
print("Creating new index")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
index.set_index_id(indexid)
index.storage_context.persist(persist_dir=index_path)
data_generator = DatasetGenerator.from_documents(
documents,
text_question_template=Prompt(
"A sample from the documents is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Using the documentation sample, carefully follow the instructions below:\n"
"{query_str}"
),
question_gen_query=(
"You are a search pipeline evaluator. Using the papers provided, "
"you must create a list of summary questions and question/answer questions. "
"Limit the queries to the information supplied in the context.\n"
"Question: "
),
service_context=service_context)
generated_questions = data_generator.generate_questions_from_nodes(num=50)
print(f"Generated {len(generated_questions)} questions.")
# save the questions into a txt file for resuse later on
with open("gdrive/MyDrive/llm-doc/questions.txt", "w") as f:
for question in generated_questions:
f.write(f"{question.strip()}\n")
with open('gdrive/MyDrive/llm-doc/questions.txt', 'r') as f:
generated_questions = f.readlines()
generated_questions = [line.rstrip() for line in generated_questions]
# importing random module
import random
eval_questions = random.sample(generated_questions,20)
eval_questionsSample result

Step 2: Evaluating Sample Response
The following code will evaluate a first question from the dataset and return YES for good quality and NO for poor answer quality
# define jupyter display function
def display_eval_df(query: str, response: Response, eval_result: str) -> None:
eval_df = pd.DataFrame(
{
"Query": str(query),
"Response": str(response),
"Source": response.source_nodes[0].node.get_content()[:500] + "...",
"Evaluation Result": eval_result.feedback
},
index=[0],
)
eval_df = eval_df.style.set_properties(
**{
"inline-size": "600px",
"overflow-wrap": "break-word",
},
subset=["Response", "Source"]
)
display(eval_df)
# use gpt4 for question generation
service_context_gpt4 = ServiceContext.from_defaults(llm=OpenAI(temperature=0.1, max_tokens=512, model="gpt-4"),
embed_model=model_norm,
node_parser=node_parser)
# call ResponseEvaluator to evaluate the responses
query_engine = index.as_query_engine()
evaluator = ResponseEvaluator(service_context=service_context_gpt4)
response_vector = query_engine.query(eval_questions[3])
eval_result = evaluator.evaluate_response(response=response_vector)
display_eval_df(eval_questions[3], response_vector, eval_result)
In my source code, I have put the async code for your reference, my OpenAI API has a rate limit so I can't not really use this method. I ended up using the loop instead of using async. Use can find the source code in the reference.
from llama_index.evaluation import BatchEvalRunner
"""
If your OpenAI API license does not have limit to call the API, then you can use this code to fasten the process
"""
## Method 1
# faithfulness_gpt4 = FaithfulnessEvaluator(service_context=service_context_gpt4)
# relevancy_gpt4 = RelevancyEvaluator(service_context=service_context_gpt4)
# runner = BatchEvalRunner(
# {"faithfulness": faithfulness_gpt4, "relevancy": relevancy_gpt4},
# workers=8,
# )
# eval_results = await runner.aevaluate_queries(
# index.as_query_engine(), queries=eval_questions[0:5]
# )
## method 2
## for normal function query 1 by 1
def evaluate_query_engine(evaluator, query_engine, questions):
total_correct = 0
all_results = []
if isinstance(evaluator, FaithfulnessEvaluator):
print("Use FaithfulnessEvaluator")
elif isinstance(evaluator, RelevancyEvaluator):
print("Use RelevancyEvaluator")
for query in questions:
print(f"Questions: {query}")
response = query_engine.query(query)
eval_result = 1 if "YES" in evaluator.evaluate_response(response=response).feedback else 0
total_correct += eval_result
all_results.append(eval_result)
time.sleep(4)
return total_correct, all_resultsStep 3: Evaluating Response Faithfulness (i.e. Hallucination)
Basically, we want to measure if the response from the query engine matches any source nodes.
# eval for Faithfulness/hallucination
query_engine = index.as_query_engine()
faithfulness_evaluator = FaithfulnessEvaluator(service_context=service_context_gpt4)
total_correct, all_results = evaluate_query_engine(faithfulness_evaluator, query_engine, eval_questions)
print(f"Faithfulness: Scored {total_correct} out of {len(eval_questions)} questions correctly.")
Step 4: Evaluating Response for the Relevancy
This step is to measure if the response + sources nodes match the query. Essentially, we want to measure if the query was actually answered by the response.
# eval for Faithfulness/hallucination
relevancy_evaluator = RelevancyEvaluator(service_context=service_context_gpt4)
total_correct, all_results = evaluate_query_engine(relevancy_evaluator, query_engine, eval_questions)
print(f"Relevancy: Scored {total_correct} out of {len(eval_questions)} questions correctly.")
Step 5: (Optional) Evaluating Response for Correctness
This is an optional step but pretty similar to the steps 3 and 4. You can find more here.
Summary + Recursive Document Agent Approach
I haven’t written any summary + recursive document post yet. It is because LlamaIndex has done an excellent on writing about that topic, you can read more at this title: Recursive Retriever + Document Agents, so no point for me to rewrite it, my intention is always to give a tutorial that you can use to prepare for production-ready or for your work or research.
A quick summary of step-by-step to build this index
First, you need to build a document agent
# load all the documents
import glob
files = []
for file in glob.glob("gdrive/MyDrive/llm-doc/data/*.pdf"):
print(file)
files.append(file)
all_docs = {}
for title in files:
doc = title.split('/')[-1].split('.')[0]
all_docs[doc] = SimpleDirectoryReader(input_files=[title]).load_data()
agents = {}
for doc in all_docs:
# build vector index
vector_index = VectorStoreIndex.from_documents(all_docs[doc], service_context=service_context)
# build summary index
summary_index = SummaryIndex.from_documents(all_docs[doc], service_context=service_context)
# define query engine
vector_query_engine = vector_index.as_query_engine()
summary_query_engine = summary_index.as_query_engine()
# define tools
query_engine_tools = [
QueryEngineTool(
query_engine = vector_query_engine,
metadata = ToolMetadata(
name="vector_tool",
description=f"Useful for retrieving specific context from {doc} "
)
),
QueryEngineTool(
query_engine = summary_query_engine,
metadata = ToolMetadata(
name="summary_tool",
description=f"Useful for summarization questions related to {doc} "
)
),
]
# build agent
function_llm = OpenAI(model = 'gpt-3.5-turbo-16k')
agent = OpenAIAgent.from_tools(
query_engine_tools,
llm=function_llm,
verbose=True
)
agents[doc] = agentThen build the recursive retriever over the agents
# define top-level nodes
nodes = []
for doc in all_docs:
doc_summary = (
f"This content contains content about {doc}. "
f"Use this index if you need to lookup specific facts about {doc}.\n"
)
node = IndexNode(text=doc_summary, index_id=doc)
nodes.append(node)
# define top-level retriever
vector_index = VectorStoreIndex(nodes)
vector_retriever = vector_index.as_retriever(similarity_top_k=1)
# note: can pass `agents` dict as `query_engine_dict` since every agent can be used as a query engine
recursive_retriever = RecursiveRetriever(
"vector",
retriever_dict={"vector": vector_retriever},
query_engine_dict=agents,
verbose=True,
)
response_synthesizer = get_response_synthesizer(
# service_context=service_context,
response_mode="compact",
)
query_engine = RetrieverQueryEngine.from_args(
recursive_retriever,
response_synthesizer=response_synthesizer,
service_context=service_context,
)Step 1 & 2: Same as the previous approach
Step 3: Evaluating Response Faithfulness (i.e. Hallucination)

Step 4: Evaluating Response for the Relevancy
What does the result tell us?
Comparison Overview
Obviously, the Summary + Recursive Document Agent approach gives us a better result. While the normal indexing strategy scored 17/20 for Faithfulness and 15/20 for Relevancy, the second approach scored 18/20 and 17/20 for Faithfulness and Relevancy respectively.
Potential Improvement
This shows that we can do a bit more work in stage 1: Indexing Stage to optimize/improve the performance of the pipeline overall. Apart from moving away from the standard index to Summary + Recursive Document Agent, we haven’t done much in terms of data processing such as cleaning or adding metadata, etc. Each iteration step will give you a quick insight into what need to do further to have a better response from the RAG app.
While the two Australian financial market and real estate outlooks I put on are short and easy to extract data, the 10K report of Microsoft and Nvidia on the other hand are quite complex and contain a lot of jargon and tables. Hence, it is hard for RAG to perform and exceed our expectations. If we can extract the tables insight the report then the question regarding to comparison between Microsoft and Nvidia perhaps won’t cause much trouble
We only evaluate the embedding/indexing in this post, you can, however, evaluate the quality of any Retriever module defined in LlamaIndex
Summary
There is no perfect solution when searching for the best way to improve RAG performance. You need to try and find and improve and repeat the circle until you find the right formula for your own app. Even if we use GPT-4 which is the most comprehensive and one of the best LLMs in the market, we still see some nuance answers from the advanced LLM model such as marking the response from GPT-3.5 as NO for Relevancy while I personally think it is an appropriate answer.
There are a few tools in the market that can help you to have a deep evaluation of your app such as Trulens, Arize AI or DeepEval. LlamaIndex has covered those tools in the official document, I highly suggest you check it out.
The RAG pipeline development process must include evaluation. You can determine the model’s areas for improvement and implement the necessary changes to enhance its performance by routinely analyzing the model.
I strongly advise you to regularly assess your model if you are building a RAG pipeline. You may use this to make sure your model is generating answers that are accurate, pertinent, and meet user demands.
Finally, in response to your comments, I’ll leave the source code for this post in my GitHub repository. I use Google Colab to run this notebook and Google Drive to store the data, you may want to change the location of data in the notebook to point to your environment.
If you enjoyed this article, please give it a clap and follow/subscribe for future publications. A clap means a lot to me knowing that what I’m doing is valuable to you. If you have any questions, please leave them in the comments section and I will attempt to respond as soon as possible.
If you need to reach out, don’t hesitate to drop me a message via my Twitter or LinkedIn and subscribe to my substack as I will cover more learning practices, especially the path of developing LLM in depth in my substack channel.
References:
Observability
LlamaIndex Evaluation
Different Modules of Evaluation
Bonus: Retrieval Evaluation Usage Pattern
Integrations: DeepEval and Ragas
Github repo
📅 There is a long-form evaluation end-to-end assessment of RAG with LlamaIndex article coming, so subscribe to not miss out.
❤️ If you found this post helpful, I'd greatly appreciate your support by giving it a heart. It means a lot to me and demonstrates the value of my work. Additionally, if you'd like to further support my efforts, you can consider a small contribution through a paid subscription.
The article<a href="https://www.planethive.ai/services/secure-chatbots-rag">RAG Chatbot</a> offers clear insights into assessing Retrieval-Augmented Generation (RAG) models. Its practical tips and examples make complex concepts easy to understand. The emphasis on evaluation metrics is particularly valuable for developers. Overall, it's a fantastic resource for anyone looking to enhance their RAG implementation.