
RAG Pipeline Pitfalls: The Untold Challenges of Embedding Table
A typical journey of building the RAG pipeline from Zero to Something and a guide on handling tables of RAG with LlamaIndex

I love the quick guide to building the Chatbot and when I first started, diving into the world of AI and chatbots it was a thrilling ride. I always get a kick out of those quick guides that show you how to whip up a Chatbot. It’s pretty magical to see how just a few lines of code can bring a bot to life. It’s like, with just a dash of code, you’ve created this tiny buddy ready to chat the day away, especially with frameworks like LlamaIndex or Langchain.

But that’s usually a Proof of Concept (PoC) stage, where things are all rainbows and unicorns. Now, moving from that PoC to something more solid, that’s where the real adventure begins. It’s one thing to create a bot that can handle a casual chit-chat and a whole different ball game to design one that’s practical, easy for folks to use, and can smartly handle complex situations thrown its way. The journey from a basic bot to a reliable buddy who can sift through complicated stuff without breaking a sweat is where the rubber meets the road.
If you need a quick guide on how to improve your RAG pipeline, please refer to my previous post
So you want to improve your RAG pipeline

LLMs are a fantastic innovation, but they have one major flaw. They have cut-off knowledge and a tendency to make up facts and create stuff out of thin air. The danger is LLMs always sound confident with the response and we only need to tweak the prompt a little bit to fool LLMs.
And if you need to evaluate your RAG performance, then this long-form post will help:

Back to our stories, here is a typical journey with LlamaIndex that I’ve experienced:
Typical Journey of Building RAG
Step 0 - A Nothing RAG:
You build a simple notebook that can answer all the information from a single document, and you feel a thrill.
Step 1 — A Navie RAG
You feel great, but now you want to apply the same thing for all of your documents, you throw a bunch of documents into a folder, apply the same approach with embedding size, OpenAI is LLM, etc. You get an upgraded version of Step 0.
But what is the catch? Well, your second PoC gets a few answers wrong, it can answer specific details but it hardly answers correctly the comparison question.
Step 2 — A not so Navie RAG
okay, just a few hiccups as expected. You go back to official documents, and do some research on SummaryIndex, Knowledge Graph, and RecursiveIndex because obviously, throwing all the documents with VectorIndex is not good enough. Yep, you get a good result. Most of the wrong answers from the Step 1 PoC are now correct answers.
But there are still a few things that are quite wrong. You ask for the number of 2019 but the bot gives you the answer from the 2023's table.

If you are unfamiliar with Index in LlamaIndex, this quick guide may help
Step 3 — A When you’ve done your research RAG
it seems like we need a better way to query table data. There is PandaQueryEngine but you hardly notice. You go back to the official documents and do some research, go through the notebook and voila, it looks like you can solve the issue of step 2 now. Humm, is it though?

Well, not quite, the PandaQueryEngine requires you to index the table and give a bit summary of that table. But how do you know how many tables of the title of each table in your document? Let’s say there are ~50 tables in the classic 10-K report. Will you index ~50 tables separately? What if you have multiple 10-K reports? Then it does not sound like a good solution at all.
Potential Solutions
In addition to the mentioned steps, it’s likely you’ve encountered other challenges such as varying results from different chunking strategies, or difficulties in managing documents with timestamps. A recent hurdle I’ve faced is ensuring the masking of PII data adheres to compliance and data governance regulations. If you need assistance with these issues, don’t hesitate to reach out to me on LinkedIn. I’d be happy to delve deeper into these challenges and discuss potential solutions.
In my opinion, step 3 is probably one of the hardest stuff. It is because PDF is one of the hardest forms to extract. You can easily extract text from PDF but it is difficult to extract tables with context from PDF files.
I have tried multiple solutions and realize there is no one solution that fits all. Some of the libraries I’ve tried may work on some particular content of PDF files but some may not.
In this article, I want to break down a few solutions I’ve tried to implement for my RAG pipeline when I build RAG for my firm.
Solution 1: Open-source libraries
Always my first thought when coming to seeking a solution. I’ve tried PyMyPDF, Tablula-py and PDFPlumber to Camelot.
Pros:
They are all good in terms of what they are made for: extract the table. Camelot is a pretty impressive framework when it can extract complex table formats.
Cons:
You get the tables from PDF? Yes. But do you know what the table is about? Because at the end of the day, you still need a table summary so RecursiveRetrieval can query data from that table for you.
A quick walk around with this issue: I use the extract the text before and the text after the table and send those text and long with the table to LLM and ask LLM for a quick summary.
Solution 2: Cloud platform.
Yep, you heard me right. I tried to utilize some of the existing solutions from vendors such as AWS with AWS Textract, Adobe’s API, Apryse SDK and Aspose.PDF for Python.
What I found is that AWS Textract and Adobe’s API stand out for what I need. However, Adobe’s API is quite expensive, I mean it is expensive API and most of the time, you don’t use all of its capability.

AWS Textract on the other hand, is quite good in general. What I found using this solution is the AI behind this tool can help you to answer the question and you can use that answer, along with your LLM to synthesise the response. Think about it like combining responses from AWS Textract + LLM to get a better and more accurate response. If you only extract text from PDF, Textract is quite cheap but if you use some endpoints like query or table query then the price is something you need to be concerned about.
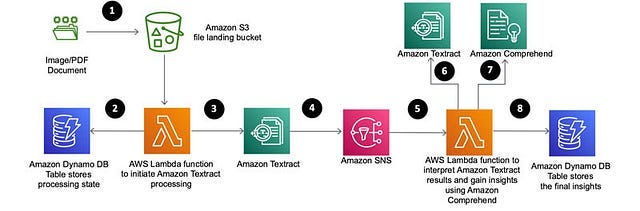
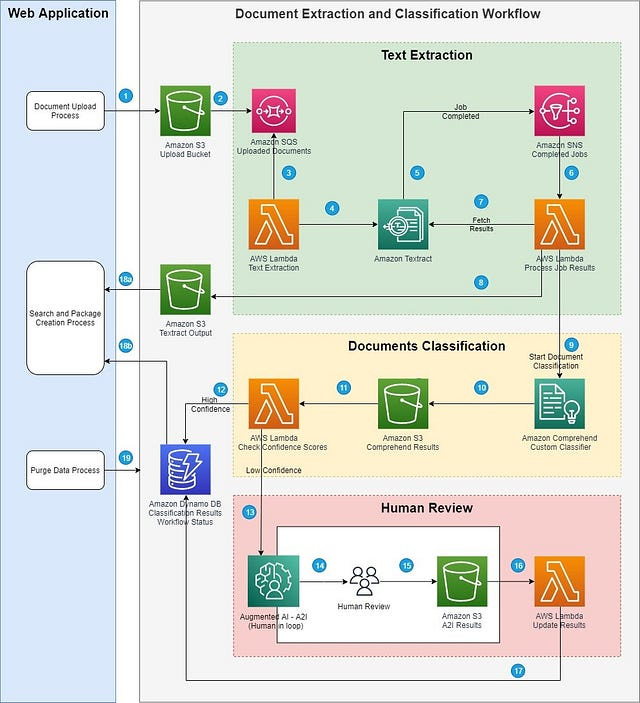
In my designed solution, there is no point in just using Textract for extracting text because I already have the open-source framework to do just that. I use query + table query to get the answer I need and synthesise the answer with LLM.
Pros:
More accurate answer
Can do complex stuff such as locate the content of the answer and you can have a visualization of where the context comes from
Easy to use
Cons:
Expensive
Slow because it is machine learning tools back.
Solution 3: This is something new from LlamaIndex.
So I’ve seen a tweet from Jerry Liu who is co-founder of LlamaIndex. I recommend you follow him to get more up-to-date on the awesome LlamaIndex

and I thought this could be a solution to solve my problem. I ended up spending some time looking into this solution. It is good overall, but not the out-of-box solution I imagined.
The full notebook on Ask queries over any tabular data OR text in a 10-K document can be found here:
llama_index/docs/examples/query_engine/sec_tables/tesla_10q_table.ipynb at main ·…
LlamaIndex (GPT Index) is a data framework for your LLM applications …github.com
So how does it work?
Firstly, we use Unstructured to parse out table and “non-table” elements from a 10-K document.
Next step, we extract a “caption” from each table with an LLM
These captions are indexed along with the rest of the text. They contain a reference to the underlying table!
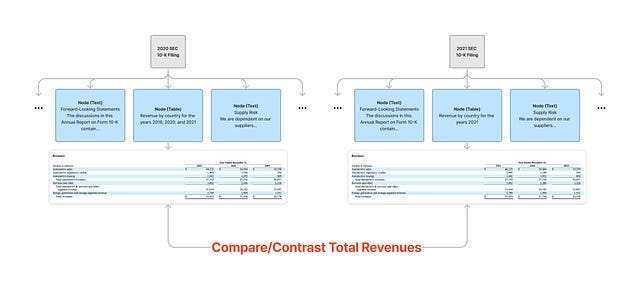
Yes, it is quite similar to my first approach and it definitely works better than trying to index the tables directly. This is because retrieving based on an entire table does not do well.
However, there are a few things you need to consider.
The solution notebook uses htm as the input data format. HTM or HTML is different compared to PDF as the structure is different. If you expect to change the input file from HTM to PDF and hope Unstructure will do its magic you may be disappointed. It is not there yet.
Original code:
elements = extract_elements("tsla-20211231.htm", table_filters=[filter_table])
table_elements = get_table_elements(elements)
text_elements = get_text_elements(elements)
len(table_elements)
-- Output--
105Change to PDF
elements = extract_elements("./data/10-Microsoft-Jun-2023.pdf", table_filters=[filter_table])
table_elements = get_table_elements(elements)
text_elements = get_text_elements(elements)
len(table_elements)
-- Output--
0There is no table in the output. Hum, concerning?
So, how do we overcome this block?
One way we can do this is to convert PDF files into HTM/HTML file format. There are plenty of open-source frameworks that can do just that but I found pdf2htmlEX is super easy to use and one of the best open-source out there for this purpose.
Note: there are few cloud vendors can convert PDF file to HTML, I will let you to do research on it and you can recommend me the best cloud vendor platforms you found for this purpose. I really want to have your collective wisdom on this one to build a better product.
Back to our open-source pdf2htmlEX, you first need to install pdf2htmlEX to your OS. Then, use the following Python function to as a middleman to convert PDF to HTML.
import subprocess
def convert_pdf_to_html(pdf_path, html_path):
command = f"pdf2htmlEX {pdf_path} --dest-dir {html_path}"
subprocess.call(command, shell=True)
input_pdf = "./data/10-Microsoft-Jun-2023.pdf"
output_pdf = "./data/10-Microsoft-Jun-2023.htm"
convert_pdf_to_html(input_pdf, output_pdf)After running this function, you should have your file in *.HTM format in the same folder. You now can use the rest of the code in the notebook to process.
Here is the result
elements = extract_elements("./data/10-Microsoft-Jun-2023.htm", table_filters=[filter_table])
table_elements = get_table_elements(elements)
text_elements = get_text_elements(elements)
len(table_elements)
-- Output--
98Conclusion
Dealing with documents full of tables can be quite challenging. Finding the right embeddings and strategies is key to taming these unruly beasts, especially as the tables become more complex. There is no one-size-fits-all solution. As you can see, it’s necessary to extract the table along with its caption, with assistance from the LLM, and to have a separate table index for each document.
The suggestions in this post are just a kick-off point and the solution from UnstructuredIO is really promising. I’m sure they will improve more of this function in the future to natively deal with tables from PDF files.
Now, I’m really keen to hear from you. What methods do you use by when it comes to handling these tricky documents? Feel free to share your thoughts in the comments below or shoot me a message directly over my LinkedIn. It’s by sharing and comparing notes that we can find more effective ways to tackle this challenge. So let’s get this conversation rolling and learn from each other!
❤️If you enjoyed this article, please give it a clap as it means a lot to me and also hit the follow for future publications. If you have any questions, please leave them in the comments section, and I will attempt to respond as soon as possible.
Want to Connect?
If you need to reach out, don't hesitate to drop me a message via my
Twitter or LinkedIn and subscribe to my Substack, as I will cover
more learning practices, especially the path of developing LLM
in depth in my Substack channel.