
Live Indexing for RAG: A Guide For Real-Time Indexing Using LlamaIndex and AWS
Step-by-Step Implementation: Building a Real-Time Indexing of Vector Database with LlamaIndex and AWS (and Pathway)

I found this tweet on X (formerly Twitter) and it is really funny somehow.

Joking aside, some of the most valuable information is found in PDFs. Anyone who can build AI systems that process and answer questions reliably around PDFs is worth following closely. It’s not an easy problem.
I’ve spent countless hours finding and using the majority of LLM solutions available today and I have to say they do a bad job at analyzing PDFs since they include a plethora of difficult-to-manage complex information, including nested tables, figures, equations, photos, and many other things. To understand what I mean, just give any of the well-known LLMs available today a try. A great deal of mistakes and hallucinations beyond anything you’ve ever experienced before

Now, back to the joke above, with the rise of RAG frameworks such as LlamaIndex and Langchain, and the explosion of Large Language Models (LLMs) in 2022, the ecosystem has evolved from a simple but functional setup to a readily deployable platform for creating full-stack applications.
A prominent illustration is LlamaIndex, my personal favorite RAG framework, which requires only a few lines of code to create a fully effective chat-with-PDFs application.
npx create-llamaWith few prompts and a few configurations, you have a ready-to-go ChatUI client with your data
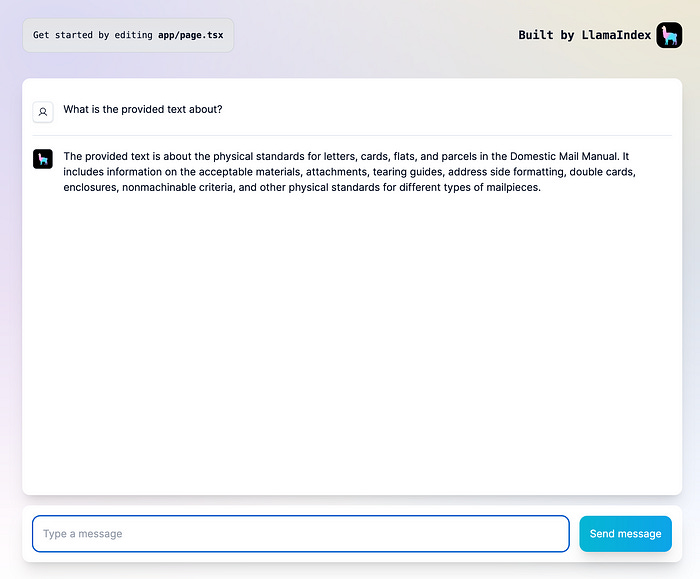
For more info, please check this guide and this guide.
So, what else has to be done by AI engineers to create an enterprise RAG application if it is that simple?? Well, plenty.
How do you re-index and live update your vector database in real time?
If you change your embedding model, how do re-embedding (along with reindexing and updating your vector database)
The monitoring aspect cannot be ignored.
Authentication / Authorization?
What if you want to change your ingestion pipeline, or want to experiment new VectorStoreIndex?
Big Concern: Scale.. Indexing 1 PDF is easy, how about 1000 or 10,000 PDFs at the same time?
And many more you will discover when you start building real production-grade, etc
Those bullet points are just starting points for you to keep in mind when coming to designing and developing your RAG, either for enterprise use cases or for customer use cases.
In the context of this post, I am primarily focused on the first bullet point. In order to keep your database up to date with the newest files, I want to investigate a number of possible approaches for re-indexing and automating the update or insertion of vectors.
Disclosure: As the headline suggests, LlamaIndex and AWS are my go-to technologies. LlamaIndex is my favorite RAG framework, and AWS is a logical choice given my depth of experience — I’ve spent the last eight years moving from software engineering to data engineering and then exploring AI engineering. You can use GCP and Azure as it is easily integrated with the reasoning and theories covered here.
Scenario
Suppose you are developing an enterprise chat platform with documents saved in AWS S3. Instead of depending on batch reprocessing overnight, you want to guarantee real-time access to the most recent information. For example, the ChatApp is expected to automatically incorporate modifications from the finance and insurance teams as they upload new pricing policies or add new claim policies to the S3 repository. This guarantees that when customers have questions, the customer service team can quickly respond by giving them the most recent information on policies and prices.
Note: I’ll assume that the reader is already acquainted with RAG pipelines and LlamaIndex. If not, feel free to peruse every one of my earlier postings, beginning with
Zero to One: A Guide to Building a First PDF Chatbot with LangChain & LlamaIndex - Part 1

Welcome to Part 1 of our engineering series on building a PDF chatbot with LangChain and LlamaIndex. Don't worry, you don't need to be a mad scientist or a big bank account to build and train a model. With the rise of Large Language Models (LLMs) such as ChatGPT and GPT-3, it's now easier than ever to build intelligent chatbots that are smarter than you…
then how to use Llama’s index, how to use storage with LlamaIndex, choose the right embedding model and finally deploy in production
If you need a quick guide on how to improve your RAG pipeline, please refer to my previous post

If you need to evaluate your RAG performance, then this long-form post will help, and for improving indexing techniques.

and a few more, for a comprehensive list of articles, please refer to this post.
Explore Open Source
My first and go-to strategy was always to look for an open-source framework designed for this kind of situation. I thought maybe someone else had faced a similar problem and came up with a solution. So instead of beginning from scratch, I concentrated my initial efforts on researching already-existing tools, hoping to draw from a wealth of knowledge and expand upon pre-existing frameworks. If I could not find any tools that would work, oh boys, the idea of turning this gap into a business opportunity became more and more alluring.
Luckily I found Pathway — a data processing framework to do just that. Now, Pathway is much much more than just a tool for reindexing and reupdating vector databases. It has developed into an all-inclusive data processing tool that is specially designed to satisfy the demands of AI applications for LLMs (Large Language Models). The Pathway-LLM open-source repository provides a specialized solution for effective data processing in the context of artificial intelligence applications. You can find Pathway-LLM in this repo
And fortunately, LlamaIndex already has an integration with Pathway for data retrievers. Does that mean I can conclude my research here and start using this combo for my work?
Well, the more I look into it, the more I feel like there is a lack of custom integration. But first, let’s look into the advantages of Pathway:
Multiple connectors — meaning you can build can connect Pathway to S3, Dropbox, Google Drive, Azure, etc
Real-time Data Syncing. As soon as you upload the document, it will be indexed instantly.
Alert setup comes in handy.
Built-in monitoring
Scalability…hum, haven’t tested it yet.
LlamaIndex integration comes in handy
So what is the downside:
You need to run and manage your server. Yep, either Docker, EC2, or Kubernetes. Pathway LLM-app needs a server.
I don’t know the underlying of how Real-time Data Syncing works. If it is constantly called S3 to get API to keep track of the uploaded data, then the cost for S3 API GET will be your burden.
Correct me if I’m wrong here, but it seems like the LlamaIndex integration is cool, however, it only supports basic vector index.
### This is a sample code for desmonstration.
transformations_example = [
TokenTextSplitter(
chunk_size=150,
chunk_overlap=10,
separator=" ",
),
embed_model,
]
processing_pipeline = PathwayVectorServer(
*data_sources,
transformations=transformations_example,
)Although I haven’t tested for scalability myself, I have seen from looking through the source code that the server uses threads to handle numerous files at once. This implies that scalability is directly related to your machine instance’s specs, recommending larger instances for best results. Furthermore, auto-scaling techniques must be used in order to effectively manage traffic variations. In order to do this, it is advised to deploy the Pathway LLM server to ECS or EKS. This will give you a flexible and scalable infrastructure that can adapt to changing workloads on the go.
You can explore this solution for yourself if you are interested. Repo is here
ReIndexing and Updating DB Architect with AWS
So the first approach hit a few things that in my opinion, it will be not a good idea to start for live indexing.
Managed Server
Lack of flexibility for indexing and retriever choices
That is why, I switch back to the conventional method since I feel it allows me a great deal of flexibility and integration to meet my needs.
Tools
Here is the tech stack we are going to use
AWS S3
AWS Lambda
LlamaIndex
(Optional) SNS and SQS,
Secret Manager
Database: ChromaDB, MongoDB, Redis
Architect Design
An overview of the high-level architect design.
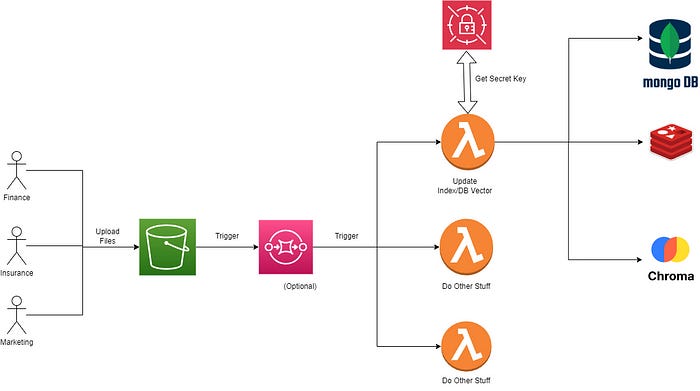
Workflow
User uploads new files to S3 Bucket
S3 Bucket is configured to trigger SQS every time there is a new file upload
SQS then trigger and distributes the message to lambda functions.
The lambda function gets the OpenAI API Key or any Key from the Secret Manager. I will skip Secret Manager in this build
A particular lambda function will respond to reindexing the document and either update or insert into ChromaDB (vector db) or MongoDB (to store index, and optional as document store) and Redis for caching.
The SQS here is totally optional, you can skip SQS and use the Lambda functions directly instead. AWS S3 does support triggering the Lambda function in event notifications.
Adding SQS here is mainly for scaling purposes. I ran into the issue where I called the lambda function directly and I got the IteratorAge issue where the thousand of the same lambda function is called at the same time.
Why do I prefer this approach?
As mentioned, this approach gives me the freedom of what I can do.
The lambda function is triggered only when there is a new file uploaded. While one particular lambda function handles the upload/insert, the other lambda function can do other things such as alerting or monitoring to sending messages to downstream applications or Slack, discord, etc, you named it.
Lambda function is serverless, and scalable, however, to set up the architect like that, it requires a certain degree of AWS knowledge. If you’ve worked with AWS for a few years, then the task above is easy. However, for someone who does not know much about how to deploy the infra like above, please keep reading.
Deploying AWS Infra
This section is dedicated to explaining and deploying the architect above via CloudFormaton with AWS CLI.
Prerequisite
Before we begin, you need to install:
Python3
Create an AWS Account and get the AWS Credential/Access Key
Next step: install SAM CLI
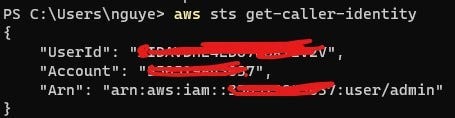
After this step, you can run this in the command line to test the connection
aws sts get-caller-identityIf you get a result like this, then you are good to go
CloudFormation Template
It is actually SAM template but the underlying SAM is CloudFormation. SAM is a higher level of CloudFormation with better syntax to develop infra as code.
You can find the full template here in my repo. I will break it down in the following section. Feel free to skip it.
Firstly, we define the template format and the parameters.
AWSTemplateFormatVersion: '2010-09-09'
Transform: 'AWS::Serverless-2016-10-31'
Parameters:
BucketName:
Type: String
Description: Name of the S3 bucket
Default: 'e2e-rag-file-uploaded'Next, we define SQS, Bucket, and QueuePolicy. The EventNotification is configured inside the Bucket resource
The VisibilityTimeout: 900 seconds in the Queue to line up with 900 seconds max of execution of the Lambda function
Resources:
E2ERAGFileUploadedSQS:
Type: 'AWS::SQS::Queue'
Properties:
VisibilityTimeout: 900
S3UploadBucket:
Type: 'AWS::S3::Bucket'
Properties:
BucketName: !Ref BucketName
NotificationConfiguration:
QueueConfigurations:
- Event: 's3:ObjectCreated:*'
Queue: !GetAtt E2ERAGFileUploadedSQS.Arn
DependsOn:
- QueuePolicy
S3BucketPolicy:
Type: 'AWS::S3::BucketPolicy'
Properties:
Bucket: !Ref S3UploadBucket
PolicyDocument:
Version: 2012-10-17
Statement:
- Action: '*'
Effect: Allow
Resource:
- !GetAtt S3UploadBucket.Arn
- !Sub
- '${varS3BucketArn}/*'
- varS3BucketArn: !GetAtt S3UploadBucket.Arn
Principal:
AWS:
- !Sub 'arn:aws:iam::${AWS::AccountId}:root'
QueuePolicy:
Type: 'AWS::SQS::QueuePolicy'
Properties:
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service: "s3.amazonaws.com"
Action:
- 'SQS:SendMessage'
Resource: !GetAtt E2ERAGFileUploadedSQS.Arn
Condition:
ArnLike:
aws:SourceArn: !Join ["",['arn:aws:s3:::',!Ref BucketName]]
StringEquals:
aws:SourceAccount: !Ref AWS::AccountId
Queues:
- !Ref E2ERAGFileUploadedSQSIn the final part of the resource, we define the Lambda functions and the execution role.
I place the main.py and requirements.txt under the functions/indexing folder. For more about the entire structure, please refer to my repo.
LiveIndexingLambdaFunction:
Type: 'AWS::Serverless::Function'
Properties:
Handler: main.main
Role: !GetAtt LiveIndexingLambdaFunctionExecutionRole.Arn
FunctionName: LiveIndexingFunction
Runtime: python3.10
Timeout: 900
MemorySize: 512
CodeUri: functions/indexing/
Events:
MySQSEvent:
Type: SQS
Properties:
Queue: !GetAtt E2ERAGFileUploadedSQS.Arn
DependsOn: LiveIndexingLambdaFunctionExecutionRole
LiveIndexingLambdaFunctionExecutionRole:
Type: 'AWS::IAM::Role'
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service:
- 'lambda.amazonaws.com'
Action:
- 'sts:AssumeRole'
Policies:
- PolicyName: LambdaS3SQSPolicy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- 's3:*'
- 'sqs:*'
- 'logs:CreateLogGroup'
- 'logs:CreateLogStream'
- 'logs:PutLogEvents'
Resource:
- !GetAtt S3UploadBucket.Arn
- !Sub
- '${varS3BucketArn}/*'
- varS3BucketArn: !GetAtt S3UploadBucket.Arn
- !GetAtt E2ERAGFileUploadedSQS.ArnLive Indexing Function
I won’t go into great depth about the implementation methodology here. You should be familiar with the essential actions if you have been reading my blogs and constantly monitoring LlamaIndex’s documents. I’ll supply you with a basic template, which you can then modify to fit your needs and add more functionality when needed.
## main function of AWS Lambda function
import llama_index
from llama_index import download_loader
import boto3
import json
import urllib.parse
from llama_index import SimpleDirectoryReader
def main(event, context):
# extracting s3 bucket and key information from SQS message
print(event)
s3_info = json.loads(event['Records'][0]['body'])
bucket_name = s3_info['Records'][0]['s3']['bucket']['name']
object_key = urllib.parse.unquote_plus(s3_info['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
# the first approach to read the content of uploaded file.
S3Reader = download_loader("S3Reader", custom_path='/tmp/llamahub_modules')
loader = S3Reader(bucket=bucket_name, key=object_key)
documents = loader.load_data()
## TODO
# ReIndex or Create New Index from document
# Update or Insert into VectoDatabase
# (Optional) Update or Insert into DocStorage DB
# Update or Insert index to MongoDB
# Can have Ingestion Pipeline with Redis Cache
return {
'statusCode': 200
}
except Exception as e:
print(f"Error reading the file {object_key}: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps('Error reading the file')
}All of the uploaded file’s details are contained in the event parameter of this lambda function, which is called by SQS. The metadata from the event can be used to improve the indexing process.
What we can do to improve this lambda function
You can speed up and improve the convenience of this lambda function in a few different ways.
If you use OpenAI API, use SecretManager to store OpenAI API
Use Layer to install the libraries such as llama-index, UnstructuredIO or any other library, this will make your deployment faster
Download upfront the data loader so the Lambda function does not need to download the loader every time
It is now your responsibility to carry out the desired functions of your live indexing feature. Use your normal indexing code, adding features such as KnowledgeGraph, SummaryIndex, and other pertinent operations. Select a suitable database to store the produced index in, such as Redis, S3, or MongoDB. This storage option guarantees that the index may be easily retrieved in the future.
Summary
While building a simple, full-stack RAG application may appear easy, developing a RAG system that is actually useful is a significant problem.
One essential component of any RAG application is live indexing, and although Pathway provides a strong base, it has some drawbacks. Since the RAG framework is always changing, your RAG application must also be flexible. To achieve a more customized and flexible outcome, developing a custom live indexing system with AWS services is a better option.
The code that is provided acts as a first step, providing the framework for your unique solution. There is plenty of room for improvement before production grade.
❤ If you found this post helpful, I’d greatly appreciate your support by giving it a clap. It means a lot to me and demonstrates the value of my work. Additionally, you can subscribe to my substack as I will cover more in-depth LLM development in that channel. If you have any questions, feel free to leave a comment. I will try my best to answer as soon as possible.
Want to Connect?
If you need to reach out, don't hesitate to drop me a message via my
Twitter or LinkedIn and subscribe to my Substack, as I will cover
more learning practices, especially the path of developing LLM
in depth in my Substack channel.