
RAG in Action: Beyond Basics to Advanced Data Indexing Techniques
Document Hierarchies, Knowledge Graphs, Advanced Chunking Strategies, Multi Retrieval, Hybrid Search, Reranking, Trade-offs and more

Some time ago, I wrote an article on enhancing your RAG pipeline and outlined seven strategies for fine-tuning LLM. These techniques and strategies have proven effective in elevating the overall performance of the RAG pipeline.
So you want to improve your RAG pipeline

LLMs are a fantastic innovation, but they have one major flaw. They have cut-off knowledge and a tendency to make up facts and create stuff out of thin air. The danger is LLMs always sound confident with the response and we only need to tweak the prompt a little bit to fool LLMs.
In this article, I aim to dig into additional technical considerations for RAG implementation. Beyond the revisited chunking technique, I will introduce other methods, including query augmentation, hierarchies, and an intriguing element I’ve recently explored: knowledge graphs. I will also explore unsolved challenges and opportunities within the RAG infrastructure space, providing potential solutions for these issues.
Quick Overview of Simple RAG Architect Designed
Back on the first day of 2023, my primary focus centred on Vector DB and its performance within the broader design landscape. However, as we approach the conclusion of 2023, significant developments have unfolded in this domain. In the design of a RAG system, I consider a few things.
The ongoing battle in the realm of LLM models between open-source and closed-source. What is the best model for my pipeline?
Should I need to fine-tune LLM or embed the model for the dataset?
Secondly, the evolution of document processing strategies has been noteworthy. Commencing the year with a reliance on document chunks alone, we now boast an array of techniques, including hierarchies, sentence windows, auto-merge, and more.
Data Retrieval techniques. We started off the year with just the k-similarity technique, and now we have recursive, hybrid search, reranking, metadata filter, multi-agent, etc.
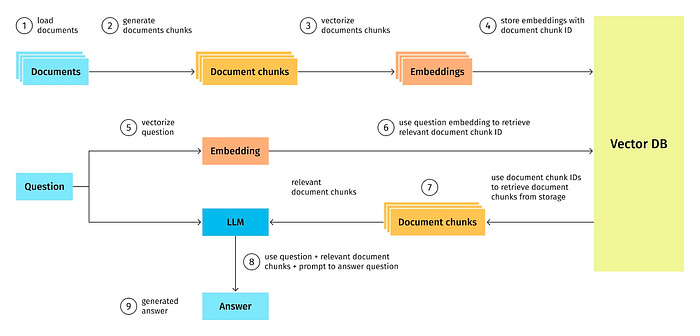
This post only focuses on preparing documents for indexing, you can find the advanced techniques discussion in the previous post here and here.
So, What makes a good data retrieval system?
Two words: relevancy and similarity.
While Relevancy refers to the degree of pertinence or significance of the retrieved information in relation to the user’s query, the Similarity, in the context of data retrieval, refers to the degree of likeness or resemblance between the user’s query and the available data.
In simple terms, similarity = word matching, and relevancy = context matching.
Vector database helps to identify the semantics of close content (similarity) but identifying relevancy or retrieving relevant content requires a more sophisticated approach.
I’ve written a lot about doing this stuff with LlamaIndex, you can check out all of my previous posts. In addition, you should check out a video from the Founder of LlamaIndex about building production RAG.

We have merely scratched the surface of RAG. In my experimentation, the success of a particular approach with one type of document does not necessarily guarantee success with other document types. Clearly, the intricate nature of table-based PDFs, such as those found in financial and insurance papers, demands significantly more sophisticated data processing and chunking strategies compared to the relatively straightforward handling of text-based documents.
The technique under discussion here should be viewed as a foundational starting point. To achieve optimal results, one may need to engage in continuous trial and experimentation with a variety of approaches, and in some cases, a combination of these approaches may be necessary for improved outcomes.
Advance Data Processing for Better Data Retrieval
Chunking Strategy
In the context of natural language processing, ”chunking” is the process of breaking up a text into manageable, clear, and significant chunks. In this scenario, working with smaller text fragments rather than bigger papers allows a RAG system to discover relevant context more quickly and accurately.
Making sure that the chunk you choose is appropriate is essential to the success of your chunking strategy. The calibre and organization of these text passages have a significant impact on how well this tactic works. To find and extract text passages that capture the essential details or context required for the RAG system, careful examination of the content and context is required. An intelligent chunking strategy improves the system’s capacity to traverse and comprehend natural language, which eventually leads to more accurate and effective information processing.
In this article, it seems like the chunk size of 1024 yields a better result

Larger chunks can capture more context, but processing them takes longer and costs more money due to the noise they generate. While smaller pieces may not fully convey the necessary context, they do have less noise. One method to balance these two requirements is to have overlapping portions. A query that combines chunks will probably be able to obtain sufficient pertinent information from a variety of vectors to produce an answer that is appropriately contextualized.
What is bad about this strategy?
This strategy’s assumption that every piece of information you need to access can be located in a single document is one of its limitations. Use solutions such as document multi-document agent with recursive method and subquery if the relevant context is spread over several separate documents.
Small-to-big chunking in conjunction with Small-to-big retrieval
The idea is selecting the optimal chunk size is sometimes not optimal because embedding/retrieving big text chunks isn’t always the best option. A large text chunk may contain a large amount of filler content that obscures the semantic representation and degrades retrieval. What if we could extract or embed depending on more focused, smaller bits, yet maintaining sufficient context for the LLM to respond appropriately? It could be beneficial to separate the text chunks used for synthesis from those utilized for retrieval. While larger text chunks provide more contextual information, smaller text chunks improve retrieval accuracy. The concept behind small-to-big retrieval is to use smaller text chunks during the retrieval process and subsequently provide the larger text chunk to which the retrieved text belongs to the large language model.
In this post, the author sets the comparison between these two simple techniques: chunking size vs small-to-big. The small-to-big seems to be a winner here but the downside is it is taking longer to query and also more expensive to do embedding data all over again.
If you need a quick setup, try a small-to-big LlamaHub’s package here
Document Hierarchies
One effective method of structuring your data to enhance information retrieval is to create a document hierarchy. A document hierarchy can be compared to your RAG system’s table of contents. By structuring the chunks, RAG systems can retrieve and process relevant and related data more quickly. Because they assist the LLM in selecting the sections that hold the most pertinent data to extract, document hierarchies are essential to the efficiency of RAG.

In document hierarchies, nodes are arranged in parent-child relationships and chunks are linked to them. A summary of the data is stored on each node, which facilitates rapid data traversal and helps the RAG system determine which chunks to extract.
BUT… Why would you need a document hierarchy?
A document hierarchy can be compared to a file directory or table of contents. While the LLM is capable of extracting pertinent text segments from a vector database, by employing a document hierarchy as a pre-processing step to identify the most pertinent text segments, you can increase the retrieval speed and reliability. In addition to increasing speed, repeatability, and retrieval reliability, this tactic can lessen hallucinations brought on by chunk extraction problems. Building document hierarchies may call for domain- or problem-specific knowledge to guarantee that the summaries are entirely pertinent to the current job.
Use case: Sagemaker’s Documentation

Within the left menu, multiple sections are present, each containing its own set of sub-sections, and each sub-section, in turn, houses its unique documents and subsequent layers of information. In a basic chunking approach, a vector query may retrieve similar code snippets from various sections, potentially leading to confusion without proper ranking.
By implementing a document hierarchy, a RAG system can significantly enhance its ability to provide accurate answers to specific questions within a given section. This hierarchical structure enables a more nuanced understanding of the context, preventing potential confusion between sections that share similar codes but possess subtle differences. For instance, when addressing a question about a specific aspect of SageMaker processing, the system can accurately discern and prioritize information relevant to that particular section, avoiding any inadvertent mix-up with SageMaker Model Building, which may share commonalities but require distinct consideration. This approach mitigates the risk of hallucination and contributes to a more reliable and context-aware RAG system.
You can have a look at this document to implement or for quick and easy testing, check out the LlamaHub here
Knowledge Graphs
Knowledge graphs are a great way to provide document hierarchies with a data foundation that is essential for maintaining consistency. In essence, a knowledge graph is a deterministic mapping of the connections among different concepts and entities. Significantly reducing the likelihood of hallucinations, a knowledge graph provides the capacity to reliably and accurately retrieve related rules and concepts, unlike a similarity search in a vector database.
One clear benefit of using knowledge graphs to represent document hierarchies is that they may be used to convert information retrieval procedures into instructions that an LLM can understand. For example, when the LLM is presented with a particular query (e.g., X), the knowledge graph can direct it by indicating that data must be extracted from a certain document (e.g., Document A) and then directed to compare the extracted data with another document (e.g., Document B). This methodical technique improves knowledge retrieval accuracy and gives the LLM the ability to produce well-contextualized replies by following logical steps, which increases the RAG system’s overall efficacy.

Knowledge graphs map relationships using natural language, which means that even non-technical users can build and modify rules and relationships to control their enterprise RAG systems. For example, A rule might say, for instance, that to respond to a query concerning SageMaker built-in algorithms, one should first consult the appropriate SageMaker document and then seek the specific algorithms inside it.
Check out this fantastic article about the Knowledge Graph with LlamaIndex. Additionally, this official document is a good starting point. If you are seeking easy implementation, check out this LlamaHub package
The wrap-up is the advanced technique in data processing apart from the basic chunking strategy that I wanted to discuss. In conjunction with these techniques, I also want to discuss two more advanced data retrieval that I think could serve well.
Bonus: 2 more Data Retrieval Techniques
I discussed a number of data retrieval strategies, including characteristics of similarity and relevancy, in my last piece. In this section, I’ll go over a few quite well-known retrieval methods that, while not novel, have worked well for me in the past.
Query Augmentation
One major problem in RAG is poorly phrased queries, which are often addressed via query augmentation. The aim is to address scenarios in which queries are devoid of particular subtleties by furnishing them with further context, hence guaranteeing optimal relevance in the generated answers. This method improves the system’s capacity to comprehend and handle a wider variety of questions, which eventually boosts RAG framework performance and user satisfaction.
Poor question formulation is frequently caused by language’s complexity. For instance, depending on the context, the same word can have two distinct meanings.

Even the superior model like GPT-4 still does not know the context of LLM that I’m referring to. This is largely a domain-specific issue.
So, what if you wanted to use industry or domain-specific terms to contextualize an LLM? Company acronyms are a simple illustration of this (for example, MLA ak metrics logs aggregation). Most LLMs find it difficult to discern between these terms. However, an MLA (Modern Language Association), MLA (Medical Laboratory Assistant) or MLA (Maximum Likelihood Estimation) are two different things when it comes to, well, MLA. My approach involved pre-processing the query and adding company-specific context to refer to the relevant segments to map “MLA”. Another more costly approach I used is fine-tuning embedding or fine-tuning the LLM model.
Check out the Query Transformation section from LlamIndex to learn more
Sub-question Planning
Sub-question planning represents the process of generating the sub-questions needed to properly contextualize and generate answers that, when combined, fully answer the original question. This process of adding relevant context can be similar in principle to query augmentation.
Let’s take the example of a question in personal finance advisor:
Investor Profile: John, a 45-year-old investor with a moderate risk tolerance, has a diversified investment portfolio consisting of individual stocks. He aims to assess the performance of his stock investments and compare it to a relevant benchmark.
Question: “How can John, a 45-year-old investor with moderate risk tolerance, evaluate the performance of his individual stock investments and compare it to a benchmark to ensure they align with his long-term financial goals?”
Sub-questions:
Metric Selection for John’s Goals:
Given John’s investment goals and risk tolerance, which specific metrics should he prioritize when assessing the performance of individual stocks in his portfolio?Tailored Benchmark for John:
Considering John’s investment profile, how can he identify a benchmark that aligns with his diversified portfolio and reflects his financial objectives?Review Frequency Aligned with John’s Strategy:
Given John’s busy schedule and long-term investment horizon, what frequency of performance review would be practical and beneficial for him?Risk-Adjusted Returns in Line with John’s Preferences:
How can John incorporate risk-adjusted metrics into the performance evaluation, considering his moderate risk tolerance and desire for stable, long-term growth?Relative Performance Analysis Tailored to John’s Portfolio:
In what ways can John conduct a relative performance analysis that specifically considers the sectors and industries represented in his diversified portfolio?Dividend Reinvestment Strategy Aligned with John’s Goals:
Considering John’s preference for long-term growth, how should he approach the reinvestment of dividends to optimize his overall portfolio performance?Long-Term Focus in Line with John’s Objectives:
Given John’s emphasis on long-term financial goals, how should he balance short-term fluctuations with a focus on sustained growth when evaluating stock performance?Adjustments and Strategy Alignment with John’s Financial Goals:
Based on the performance assessment, what specific adjustments, if any, should John consider to ensure his stock investments align with his broader financial strategy and retirement plans?
A bit far-fetched that the existing sub-query engine can do this. However given the amount of training dataset for fine-tuning LLM. We would be able to see something like that soon
To find the relevant sub-question that needs to be addressed in order to properly answer the top-level inquiry, LlamaIndex currently uses the aforementioned technique in addition to others. LlamaIndex also uses a number of different techniques, most of which are alterations of the fundamental idea mentioned previously. Together, these many strategies offer a thorough and sophisticated methodology that maximizes response relevance and accuracy within the RAG system.
This method has been criticized for introducing manual involvement into the reasoning process and for the impossibility of imagining every possible sub-question for every possible question. That is accurate. Considering the current state of LLMs, one should avoid trying to reproduce every potential sub-question and instead aim to intervene with external reasoning rules only when LLMs are about to fail.
Multi-documents with Recursive Techniques
A lot more needs to be discussed about this approach. It is slow but it is kinda good to find the correct answer. Find out more here and here as it is too long to put into a single post
Last Step: Combining Advance Data Processing and Advance Data Retrieval
This is where the controversial raise, you seriously need to think about the trade-off here. You either get the speed of the response, or trade money, and time for a better RAG response.
Think about this as a Lego game where you stack all the pieces together. The more you put on top of the layers, the better Lego you have but also the slower the process becomes. And you MUST try multiple combinations to figure out what is the best combination for your documents. There is no one-size-fits-all architect you can use at all.

The image above illustrates how you can put multiple retrievals on top of your query engine to yield a better result. In addition to this, you can also try multiple data processing techniques that we discuss above.
Knowledge graph can enforce consistent retrieval for certain key topics and concepts where the relationships are known.
For example: Apart from the Summary Index, Vector Index and Graph Index above, you can add another VectorIndex with Document Hierarchies, you can also add another VectorIndex with SentenceWindows or Small-to-big chunking.
When it comes to retrieval, you can have multiple retrieval plus hybrid search then use the Reranking to get the best match for your query.
When it comes to query engines, you can try multiple query planning techniques as we discussed above and stack them all together.
Multiple responses from multiple query engines will be sent to LLM to get the final answer.

Unsolved problems in RAG that represent future opportunities
There is no one-size-fits-all for data processing. Cost efficiency is a concern when combining multiple data processing for multiple query engine indexes.
Significant opportunity to build or improve a vector database that does better in terms of auto-retrieval.
Can we combine a knowledge graph with a traditional vector database?
Any easy way to handle ever-changing documents rather than a programmatic way?

Personal Note
Most likely, this is the final RAG/LLM post for 2023. I’ll put some effort into creating a LlamaHub that combines several data indexes and numerous data retrieval. The above-mentioned RAG pipeline architecture only displays half of the equation. Perhaps another post will be needed to complete the remaining half regarding various data indexes using various methodologies. Next year, I’ll develop a new LlamaHub package and publish it.
Although I find LLM to be fascinating, I believe that organizations are hesitant to make the next significant move. Although there is a lot of talk about how AI, and specifically LLM, might change sectors, adoption is still moving slowly, mostly because businesses are reluctant to take a clear stand in the market. This leads to nearly every company reaching the “only talking AI stage” rather than the “action stage”.
Numerous businesses have made progress in incorporating AI — including the powerful powers of LLM — into their in-house systems. But moving from internal use to wide market appeal and focusing on current users presents a unique set of difficulties. It necessitates a strategic approach that goes beyond the use of technology and explores the domains of user experience, market dynamics, and industry acceptance.
Large Language Models (LLM) in particular, and artificial intelligence (AI) in general, are set to thrive in the coming year, and it is very interesting to see how they will be incorporated into common products. The expectation of eventually realizing Artificial General Intelligence (AGI) is fueled by the significant investments made in AI startups, the creative minds behind the latest advancements, and the availability of more powerful yet affordable chips, even though the full integration of AGI into our personal lives may take some time.
The coming years hold the promise of unprecedented advancements, bringing AI one step closer to its revolutionary potential in a wide range of fields and applications.
As 2023 draws to a close, I’ve been thinking about how software development will be approached in the future. It is my firm belief that startups and companies should refocus their efforts to create platforms instead of focusing on creating individual AI-centric products or applications. I believe that the existing “application/product”-centric model will eventually lose its dominance as Artificial General Intelligence (AGI) advances.
Businesses should build a more flexible and scalable foundation that supports a range of AI services and functionalities by investing in platform development. This strategy is in line with the way artificial intelligence is developing, where integration between many applications and domains is becoming more common. Platforms can act as a flexible framework that promotes cooperation, facilitates innovation across a range of use cases, and enables the smooth integration of various AI technologies. With the software development landscape constantly changing, the strategic focus on platform architecture indicates a forward-thinking strategy to utilizing AI to its fullest potential.
That’s it for now, everyone. As we say goodbye to 2023, a year that saw incredible advancements in the field of artificial intelligence, I can’t help but be excited about what 2024 may bring. I really excited about the next AI initiatives, and I can’t wait to see and tell you all about their progress and advancements. I genuinely hope that my articles on 2023 have inspired others and helped them explore this exciting field. The positive reception and tremendous love I’ve received for my 2023 articles have been immensely rewarding, and I sincerely hope that they have ignited a spark and assisted individuals in getting into this dynamic field.
The audience’s support and kind remarks mean the world to me and give me the incentive to keep going on this road. I’m excited to explore new AI frontiers and work on LLM projects in the coming year and to share my discoveries and thoughts with the community, which has always been so encouraging.
Cheers to a bright 2024 full of advancements, expansion, and more research and development in the field of artificial intelligence!

As usual, if you need to reach out, please don’t hesitate to drop me a message via my Twitter or LinkedIn

References
https://llamahub.ai/
https://docs.llamaindex.ai/en/stable/
https://neo4j.com/developer-blog/advanced-rag-strategies-neo4j/