


The Challenging Journey of Building an AI-Powered Knowledge Base: Ingestion Pipeline Development - Part 2
From Manual Extraction to Automated Brilliance: Overcoming Challenges in Building a Robust AI Knowledge Base

Previous Posts:

Introduction
In my previous post of part 1, I shared the journey of developing a multi-agent AI application integrated with Slack for internal use. The response has been overwhelming, with over 150 employees using it since launch and more than 1,000 questions answered. Today, I want to take you deeper into one of the most challenging aspects of this project: creating an efficient and comprehensive ingestion pipeline for our knowledge base.

This post will be a detailed exploration of the obstacles I faced, the solutions I developed, and the lessons I learned along the way. Whether you’re a seasoned data engineer or just starting your journey in AI-powered knowledge management for your company or your enterprise, I hope you’ll find valuable insights that you can apply to your own projects.
The Initial Hurdle: Incomplete Data Extraction
When I first started on this project, I made a mistake: I assumed that manually downloading and extracting data from our Confluence Space would be sufficient. Oh boy, how wrong I was!
This approach quickly revealed itself to be awfully inadequate for several reasons:
Incomplete data: Manual extraction often leaves out crucial information, especially from complex pages with multiple media (image, diagram.io) and attachments (csv, excel, Sharepoint). Well, it is actually leave those media in another separated folder
Lack of structure: As mentioned, if it leaves out the media, then how come the structure can be similar to the structure present in Confluence? So it is makings difficult to maintain context.
No automatic updates: Manual extraction meant that keeping the knowledge base up-to-date. You either extract weekly or monthly and who know daily. It does not extract what has changed only, it extracts everything (EVERYTHING)
Key Insight: The quality of your AI’s outputs is directly proportional to the quality and comprehensiveness of your data ingestion process. Don’t underestimate the importance of this foundational step!
Attempts at Improvement
Realizing the shortcomings of my initial approach, I tried various methods to improve knowledge embedding:
In the world of AI and machine learning, data preparation is like cooking. No matter how expensive your oven is, if you start with low-quality ingredients, you’ll never create a masterpiece — my quote
Experimenting with different vector embeddings
Adjusting chunking strategies and use other chunking strategies approach
Fine-tuning retrieval algorithms and use reranking
etc, etc
Despite these efforts, the improvements were marginal at best. I was gaining small percentage increases in accuracy, but nothing that truly transformed the quality of our knowledge base.
This experience was a reminder of a common pitfall in traditional machine learning: the expectation that simply feeding raw data into an algorithm will yield optimal results. In reality, successful ML projects require extensive feature extraction, engineering, and selection. (Thankfully, we now have AutoML to handle much of this complexity in many scenarios.)
The Need for Sophisticated Data Processing
I look closer in the extracted data and realise how bad the extraction was:
Fragmented Content: Attachments were stored in separate folders, disconnected from their context in the main document.
Lack of Metadata: Essential information about document creation, last edit, and relationships between documents was missing.
Manual Update Nightmare: Updating the knowledge base daily or even intra-day was impractical and error-prone when done manually.
What about rich media content: Our Confluence space was filled with diagrams, roadmaps, and images that existing from other third parties (Miro, diagram.io, etc) and at the time I worked on this, AWS did not offer multi-modal embedding.
Tip: When dealing with complex, multi-modal data sources like Confluence, always try to preserve the original context and relationships between different elements. This context is often as valuable as the content itself.
It became clear that I needed to develop a more robust solution that could:
Update the Confluence data daily or even intra-day to maintain an up-to-date knowledge base
Selectively update the vector database with new or modified documents, and remove embeddings for deleted files
Extract or embed images and ensure attachments were included in the same file
Preserve the structure and context of complex documents
The Journey to a Better Solution
What impressed me most was the team’s ability to quickly pivot when they realised the limitations of their initial approach. It’s a testament to the importance of agility in AI development. You need to be prepared to throw out your assumptions and start fresh when the data demands it
Day 1: Exploring Confluence Connectors
On the first day of this new approach, I decided to explore existing Confluence connectors. After all, why reinvent the wheel if someone has already solved this problem?
I discovered that LlamaIndex, the framework I was using for our knowledge base, offered a Confluence connector. Excited by this prospect, I quickly implemented a basic version:
pip install llama-index-readers-confluenceThe user can optionally specify OAuth 2.0 credentials to authenticate with the Confluence instance. If no credentials are specified, the loader will look for CONFLUENCE_API_TOKEN or CONFLUENCE_USERNAME/CONFLUENCE_PASSWORD environment variables to proceed with basic authentication.
[!NOTE] Keep in mind
CONFLUENCE_PASSWORDis not your actual password, but an API Token obtained here: https://id.atlassian.com/manage-profile/security/api-tokens.
# Example that reads the pages with the `page_ids`
import os
from llama_index.readers.confluence import ConfluenceReader
base_url = "https://yoursite.atlassian.com/wiki"
page_ids = ["<page_id_1>", "<page_id_2>", "<page_id_3"]
os.environ['CONFLUENCE_USERNAME'] = "<your email>"
os.environ['CONFLUENCE_PASSWORD'] = <"your api token>"
reader = ConfluenceReader(base_url=base_url, oauth2=oauth2_dict)
documents = reader.load_data(page_ids=batch_page_ids, include_attachments=False)However, this initial approach had several limitations:
It only provided plain text
It struggled with table structures due to the text-only format.
Complex elements like image diagrams and Miro boards were completely lost.
For the attachment, it use other framework to extract the text from the it, leave out the crucial information of inference.
To address these issues, I decided to modify the Confluence Reader to return HTML files instead of plain text. Here’s how I approached this:
This is the original code, let modify it to get better result:
Step 1: add the
## add the get function to get the confluence object
def get_confluence(self):
return self.confluenceStep 2: get raw data instead of text
## in the process_page function, remove the conversion of raw data to text
## use this instead
text=str(page["body"]["export_view"]["value"]) + "".join(attachment_texts)Now, with this simple change, the reader function will return the document in the HTML format. You can just simple write file_name.html from documents.
This improvement preserved more of the original document structure, including basic HTML elements and images. However, it still fell short when it came to handling diagrams, Miro boards, and other plugin-generated content.
Day 1 Midnight:
After a frustrating day of trying to preserve complex document structures, I couldn’t sleep on that night at all. During a late-night meditation session (yes, I meditate when I can’t sleep — it’s surprisingly productive!), I had a breakthrough: PDF files could be the answer.
Day 2: The PDF Epiphany
The realization was simple yet powerful: By extracting documents as PDFs, we could preserve diagrams, roadmaps, and other rich content exactly as they appeared in the original document. This approach would allow us to handle both HTML (for plain text, tables, and images) and PDF (for documents with complex diagrams and attachments) formats.
Here’s how I implemented this dual-format extraction:
Step 1: change the process_page from just simple HTML to check the content of the file. As you can see, if the page contains diagram.io or roadmap-macro, I will export it as PDF format. Otherwise, HTML file. I also return other information that is need for processing later such as file type, page_id, page_title, etc
text = str(page["body"]["export_view"]["value"])
if "diagram.io" in text or 'drawio.png?api=v2' in text or 'roadmap-macro-view' in text:
print("---- Processing PDF")
return "pdf", page["id"], page["title"], self.export_pdf(page["id"])
else:
print("---- Processing HTML")
return "html", page["id"], page["title"], Document(
text=str(page["body"]["export_view"]["value"]) + "".join(attachment_texts),
# text=text,
doc_id=page["id"],
extra_info={
"title": page["title"],
"page_id": page["id"],
"status": page["status"],
"url": self.base_url + page["_links"]["webui"],
},Step 2: Modify load_data function. Nothing too drama, all you need to do is to get more information from the process_page above
docs = []
for page in pages:
file, id, title, doc = self.process_page(page, include_attachments, text_maker)
docs.append({
"file_format": file,
"page_id": id,
"page_title": title,
"doc": doc
})This approach solved many of our previous issues:
Complex diagrams and attachments were preserved in their original form.
We maintained the option of easy text extraction from HTML when needed.
The visual layout and structure of documents were kept intact.
However, this solution brought its own challenges, particularly in terms of processing and storing these larger, more complex files. But we’ll get to that in a moment.
Tip: Sometimes, the best solutions come from thinking outside the box. Don’t be afraid to combine old technologies (like PDFs) with cutting-edge AI techniques if it solves your problem effectively.
Day 3: Implementing Gradual Updates
With our new extraction method in place, the next challenge was to enable daily or even intra-day updates. Manually running the extraction process for thousands of documents multiple times a day was simply not feasible.
To solve this, I developed a system to track document metadata and process only the changes:
A metadata crawler script to fetch and store document metadata in JSON format
A comparison mechanism to identify new, updated, or deleted documents
An ingestion script to process only the changed documents in subsequent runs
Here’s a simplified version of the metadata crawler:
Note: instead of using space parameter to fetch everything from particular space, I use recursive approach by fetching the main page_id then loop through all the children and nephew to get all the other pages. The reason is because loading via space parameter is slow and I need a way to do this async or multi threading to improve speed. More on it later.
## similar to the first config, only this time, you point to your modifed Confluence reader
reader = ConfluenceReader(base_url=base_url)
confluence = reader.get_confluence()
def get_page_metadata(page_id):
"""Fetch metadata for a single page."""
page = confluence.get_page_by_id(page_id, expand='version')
if not page:
return None
return {
'id': page['id'],
'title': page['title'],
'url': page['_links']['base'] + page['_links']['webui'],
'last_modified': page['version']['when']
}
def write_metadata_to_file(metadata, directory):
filename = os.path.join(directory, f"{metadata['id']}.json")
existing_data = read_json_file(filename)
new_updated_date = datetime.strptime(metadata['last_modified'], "%Y-%m-%dT%H:%M:%S.%fZ").date()
if existing_data:
current_date = datetime.strptime(existing_data['last_modified'], "%Y-%m-%dT%H:%M:%S.%fZ").date()
if current_date == new_updated_date:
return
print(f"===Updating: {metadata['id']}")
else:
print(f"===Creating: {metadata['id']}")
with open(filename, 'w') as file:
json.dump(metadata, file, indent=4)
def fetch_page_and_children(page_id, pages_metadata):
"""Recursively fetch metadata for a page and its children."""
page_metadata = get_page_metadata(page_id)
if page_metadata:
print(f"Getting metadata for main page: {page_metadata['id']} - {page_metadata['title']}")
child_pages = list(confluence.get_page_child_by_type(page_id, type='page'))
if child_pages:
page_metadata['child_pages'] = [
{
'page_child_id': child['id'],
'page_child_title': child['title'],
'page_child_url': f"{base_url}{child['_links']['webui']}"
}
for child in child_pages
]
pages_metadata.append(page_metadata)
write_metadata_to_file(page_metadata, metadata_path)
## I spoiled you right here by giving you the code to improve the speed of getting metadata
## usually will be just sequential load. So you are welcome
with ThreadPoolExecutor() as executor:
futures = [executor.submit(fetch_page_and_children, child['id'], pages_metadata) for child in child_pages]
for future in as_completed(futures):
future.result()
def get_all_page_metadata(start_page_id):
"""Fetch metadata for all pages starting from the given page ID."""
pages_metadata = []
fetch_page_and_children(start_page_id, pages_metadata)
return pages_metadata
def get_all_page_metadata(start_page_id):
"""Fetch metadata for all pages starting from the given page ID."""
pages_metadata = []
fetch_page_and_children(start_page_id, pages_metadata)
return pages_metadata
And the main function:
root_page_id = "<your root_id of your confluence space>"
all_metadata = get_all_page_metadata(root_page_id)
print(f"Number of documents: {len(all_metadata)}")This system dramatically reduced the processing time for updates, as we were no longer reprocessing unchanged documents. I also spoiled you with the multi-threading code ready and recursive programming to improve the speed. So you are welcome.
Now, this is the section to implement confluence_doc_ingestion
## same setup of the metadata
# first, we get all the page from metadata folder
def get_all_page_ids_from_local():
days_ago = datetime.now().date() - timedelta(days=1)
all_page_ids = []
for root, dirs, files in os.walk(metadata_path):
for file in files:
file_path = os.path.join(root, file)
modified_time = datetime.fromtimestamp(os.path.getmtime(file_path)).date()
created_time = datetime.fromtimestamp(os.path.getctime(file_path)).date()
if modified_time >= days_ago or created_time >= days_ago:
id = file_path.split("/")[-1].replace(".json", "")
all_page_ids.append(int(id))
return all_page_ids
# function to write down document
def write_document(doc):
title = doc['page_title'].replace("/", '-').replace(" ", "_").strip()
file_format = doc["file_format"]
page_id = doc["page_id"]
document = doc["doc"]
print(f"====Writing for {title}")
if file_format == 'pdf':
if len(document) > 10:
with open(f"{content_path}/{page_id}-{title}.pdf", 'wb') as file:
file.write(document)
elif file_format == "html":
if len(document.text) > 10:
with open(f"{content_path}/{page_id}-{title}.html", 'w') as file:
file.write(document.text)
def load_batch(batch_page_ids):
print(f"loading: {batch_page_ids}")
documents = reader.load_data(page_ids=batch_page_ids, include_attachments=False)
for document in documents:
write_document(document)
def load_documents():
page_ids = get_all_page_ids_from_local()
batch_page_ids = [page_ids[i:i + 30] for i in range(0, len(page_ids), 30)]
print(f"There are {len(batch_page_ids)} batch_ids")
with concurrent.futures.ThreadPoolExecutor() as executor:
for i, batch in enumerate(batch_page_ids):
print(f"Loading for the batch: {i}")
executor.submit(load_batch, batch)
if __name__ == '__main__':
if not os.path.exists(content_path):
os.makedirs(content_path)
start = time.time()
load_documents()
end = time.time()
print(f"Total: {end-start}")But we still had one major problem: the lack of multi-modal embedding capabilities. To address this, I implemented a creative workaround:
For each document, I sent the entire content (HTML or PDF) to an LLM
The LLM generated a summary, descriptions of media elements, and 10 potential questions related to the document
This processed information was then stored in the corresponding file format and saved on S3
<This code section, I will leave you to work on it as it quite straight forward>
This approach allowed me to capture the essence of complex documents, including their visual elements, in a text format that could be easily embedded and searched.
Day 4: Optimization for Efficiency
While our new system was functionally superior to our previous attempts, it was painfully slow. Processing our entire Confluence space took hours, which was unacceptable for frequent updates.
To address this, I refactored the code to use multi-threading with asyncio, dramatically reducing processing time:
For metadata, I already spoil with the code above
## I spoiled you right here by giving you the code to improve the speed of getting metadata
## usually will be just sequential load. So you are welcome
with ThreadPoolExecutor() as executor:
futures = [executor.submit(fetch_page_and_children, child['id'], pages_metadata) for child in child_pages]
for future in as_completed(futures):
future.result()For the content ingestion, all you need to do is changing the load_batch function to this:
def load_batch(batch_page_ids):
print(f"loading: {batch_page_ids}")
documents = reader.load_data(page_ids=batch_page_ids, include_attachments=False)
with concurrent.futures.ThreadPoolExecutor() as executor:
executor.map(write_document, documents)The results were dramatic:
Metadata extraction: from 10 minutes to 50 seconds
Confluence extraction: from 55 minutes to 3 minutes
LLM parsing: from 80 minutes to around 15 minutes (with some throttling error processing)
These optimizations brought our total processing time down from over 2 hours to about 20 minutes, making frequent updates feasible.
Day 5: Deploying the Improved System
With our optimized pipeline in place, it was time to deploy the new system. Here’s what the process looked like:
Uploaded the processed data to S3
Cleared previous vector embeddings
Created a new knowledge base using hierarchical embedding from AWS Bedrock with S3 connector
Ran the sync process and waited for completion
The results were significant: our AI agent could now answer questions about table relationships, high-level diagrams, and image-based content that was previously inaccessible. The quality and comprehensiveness of responses improved dramatically, leading to increased user satisfaction and adoption.
Next Steps: Automating the Pipeline
While our new system was a vast improvement, there were still opportunities for further automation and optimisation. Here are the next steps I’m considering:
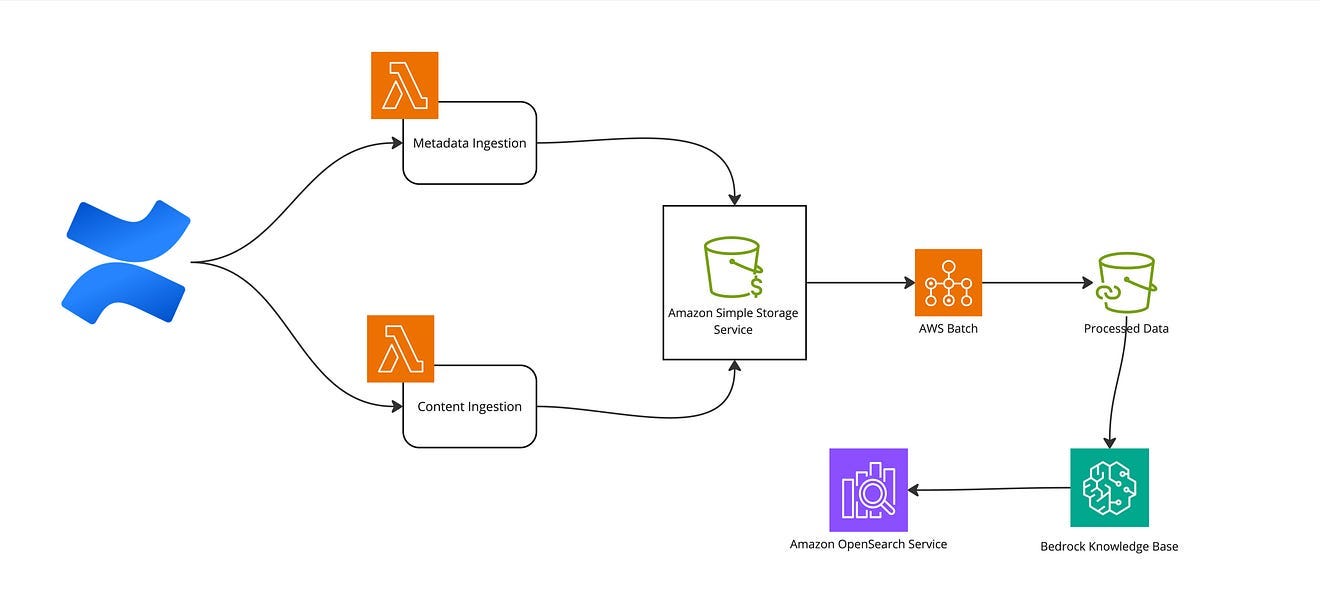
Deploy scripts as separate Lambda functions: This would allow for better scalability and easier management of different components of the pipeline.
Use AWS Batch for LLM parsing: This could help manage the computational load of processing documents through the LLM more efficiently as it takes more than 15 minutes (limitation of AWS Lambda)
Store metadata on S3 instead of locally: This would improve durability and make it easier to share state between different parts of the system.
Orchestrate the workflow using Step Functions: This would provide better visibility into the process and make it easier to handle errors and retries.
Here’s a conceptual diagram of this proposed architecture:
Key Takeaways
Start simple, but be prepared to iterate: Our initial approach was too simplistic, but it helped us understand the real requirements of the system.
Preserve context and structure: Simply extracting text is often not enough. Maintaining the original structure and context of documents is crucial for a high-quality knowledge base.
Think critical about data processing: Our use of PDFs and LLM processing for multi-modal content was unconventional but effective.
Optimise: The difference between a 2-hour and a 20-minute processing time can be the difference between a system that’s used and one that’s abandoned.
Plan for automation from the start: While manual processes can work for proofs of concept, any production system needs to be automated for reliability and scalability.
Conclusion
As I wrap up today's post of this deep dive into our journey, I’m reminded of a quote from Grace Hopper, a pioneer in computer science:
“The most dangerous phrase in the language is, ‘We’ve always done it this way.’
This sentiment encapsulates the spirit of innovation that drove our project. We constantly questioned our assumptions, weren’t afraid to discard approaches that weren’t working, and always kept pushing for better solutions.
Building an efficient ingestion pipeline for an AI-powered knowledge base is a complex challenge that requires creativity, persistence, and a willingness to iterate on your solutions. Throughout this journey, we’ve seen how each problem we solved opened up new possibilities and challenges.
Remember, perfection is often the enemy of progress. Embrace the concept of “Wabi-Sabi” — the Japanese art of impermanence — and focus on gradual improvements. Your users will appreciate the evolving capabilities of your system, even if it’s not perfect from day one.
I hope that by sharing this journey, I’ve provided some insights and inspiration for those of you facing similar challenges in your AI projects. Every project is unique, but the principles of iterative improvement, creative problem-solving, and relentless optimization are universally applicable.
What challenges have you faced in building knowledge bases or AI systems? How have you overcome them? I’d love to hear your experiences and insights in the comments below.
In the next post, I will talk about the second iteration of the bot which is SQL Agent. It all started with “Hey Ryan, awesome work with your AI bot. When we can use it to query our database”.
❤ If you found this post helpful, I’d greatly appreciate your support by giving it a clap. It means a lot to me and demonstrates the value of my work. Additionally, you can subscribe to my substack as I will cover more in-depth LLM development in that channel. If you have any questions, feel free to leave a comment. I will try my best to answer as soon as possible.
Want to Connect?
If you need to reach out, don't hesitate to drop me a message via my
Twitter or LinkedIn and subscribe to my Substack, as I will cover
more learning practices, especially the path of developing LLM
in depth in my Substack channel.References
All of my previous blog posts of LLM: https://medium.com/@ryanntk/all-of-my-llm-and-rag-articles-c4b0848b0a21
Agentic Approach with LlamaIndex: https://docs.llamaindex.ai/en/stable/use_cases/agents/
Confluence Reader: https://llamahub.ai/l/readers/llama-index-readers-confluence?from=
AWS Bedrock Document: https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html