
Building a Multi-Agent AI Application with LlamaIndex, Bedrock, and Slack Integration: A Technical Journey — Part 1
Learn how to develop a multi-agent AI application with Slack integration. Explore planning, development, and key insights for building a robust knowledge-sharing solution.


Hello everyone,
I’m back after a busy few months since my last blog post (6 months and 13 days exactly).
It has been busy for me for the last couple of months as I’ve been working on an AI-powered solution with multi-agent AI integrated with Slack for internal use. The project has been a great success, with over 150 employees using it since launch and it has answered more than 1,000 questions so far. Quite impressive given no wide internal marketing and the AI app has launched in only 1 month.
It has been a great experience working on this app. In this post and the subsequent posts, I want to share the journey of developing this multi-agent AI application, what I’ve learned, what worked, what didn’t, and some tips to help you get started.
Note: I’ll assume that the reader is already acquainted with RAG pipelines and LlamaIndex. If not, feel free to peruse every one of my earlier postings.
Another note: Since I wrote those articles long ago, some of them may be outdated already. Always refer to the latest version of LlamaIndex to get up-to-date documents.
Why Did We Create This Bot?
People don’t buy what you do, they buy why you do it.
I have ingrained this mindset into everything I create. The key question I always ask myself is, “Why will people want to buy what I’m building?”
We have an industry-leading Data Platform that processes over 1TB of data daily in real-time. Yep, no kidding — our Data Platform is comprehensive, highly complex, a single source of truth, and mature. For SMEs, it stands as one of the industry’s top standards. With more than 7,000 tables and views ranging from traditional to modern data warehouses. We are planning to migrate our old traditional data warehouse to our new, modern one. However, this transition is lengthy, and users often struggle to navigate the underlying business logic and table structures. Additionally, we run over 200 pipelines around the clock, managed by a team of more than 100 data engineers.
A single blog post to describe how comprehensive and mature of our Data Platform is not enough. It is not only a platform but also a framework for Data engineers to easily integrate the ETL logic to start a pipeline as well as observability.
Alright, alright, you are bragging about your internal Data Platform, so what does it has to do with your multi-AI agent?
Our team frequently receives questions from the business side about data. We don’t have “the ones who know it all” available 24/7 to answer stakeholder questions, so it is always time-consuming to go from asking to getting answers, which slows down their workflows as they wait for responses. While our Confluence is packed with over 3,000 up-to-date documents for knowledge sharing, searching and sifting through them can be time-consuming.
I aimed to streamline our knowledge-sharing process to help business stakeholders find answers immediately. With the advent of Gen AI technology, I saw the perfect opportunity to develop a solution.
So, in conclusion why I build this AI Agent:
Streamline our knowledge-sharing process with the knowledge base from Confluence
Efficiently addressing the business query of “What” questions or anything about our Data Platform, like issues and how to resolve it and how-to docs.
Planning Phase
Iteration 1: Proof of Concept (PoC)
I want something that is dead simple so I can show immediately the ability of the AI Agent to users.
A journey of a thousand miles begins with a single step.
I decided to start small with a single agent so I began with a simple Gen AI chatbot that had knowledge of all the Confluence documents related to our Data Platform.
The objective of this PoC
Minimize costs as much as possible.
Avoid complicated or self-managed infrastructure, with a preference for serverless solutions.
Secure, secure and secure
Utilize the AWS stack, as we have dedicated security and cloud teams specializing in AWS cloud services.
These 3 objectives will shape my choices toward the tech stacks I chose.
UI/UX
Firstly, what should be the front end? There are several options
Custom Front End with React
Streamlit and Gradio were ruled out as they are more suited for demos than what I intend to build. Chainlit has many useful features but lacks chat history storage options unless upgraded to an enterprise license, which was costly. A custom front end was too much work, and other open-source solutions were not production-ready and lacked customization options.
Not to mention that the options above require self-deployment and self-managing, which violates objective #2.
Other AI cloud providers outside AWS is ruled out as it follow the restrictions of #3 and #4.
I asked myself: if not those options, what should I choose that is not self-managed but also widely used, making it easier to reach the user? Well, the answer had been there all along, and everyone pretty much uses it every day. The one and only app — Slack.
Finally, I chose Slack as the user interface since everyone in the company uses it. Developing a Slack chatbot makes it immediately available for everyone in the company to use without the need to manage a front-end server. Additionally, it keeps all the chat history — yay! So, Slack it is.
Dataset
The next step is to get the dataset for LLM to query.
The easiest way is to extract all documents from the Confluence space into HTML files, totaling over 3,000 documents.
LLM Provider
Given our deep integration with Amazon and high-security concerns, I chose AWS Bedrock as the main LLM provider. Its security certifications and API pricing per request model align perfectly with our needs. This approach is cost-effective at the initial stage, avoiding the need to spend thousands to spin up an LLM server, which would violate #1 and #2.

Vector Index
I’ve been using Chroma and Pipecone for most of my work previously, but when coming to develop a PoC for my company. I avoid using these two databases as Chroma requires the need to maintain infrastructure, and Pinecone is simply a no as I mentioned, we have very high security standards to protect our data. No third-party data storage is RULE. So I use OpenSearch Serverless.
I’ve been using Chroma and Pinecone for most of my work previously, but when it came to developing a PoC for my company, I avoided these two databases. Chroma requires infrastructure maintenance, and Pinecone is not an option due to our high-security standards to protect our data — no third-party data storage is allowed. So, I chose OpenSearch Serverless instead.

LLM Architecture
I opted for Retrieval-Augmented Generation (RAG) over fine-tuning LLMs due to cost considerations. As discussed in previous blog posts, this type of task is particularly suited for RAG architecture rather than fine-tuning.
For the LLM framework, I used LlamaIndex as the main framework and LangChain for additional tasks.
To handle server requests, I chose AWS Lambda Functions over ECS or EC2. While ECS is not self-managed, it introduces unnecessary complexity, which I aimed to avoid.
The HLD architecture:
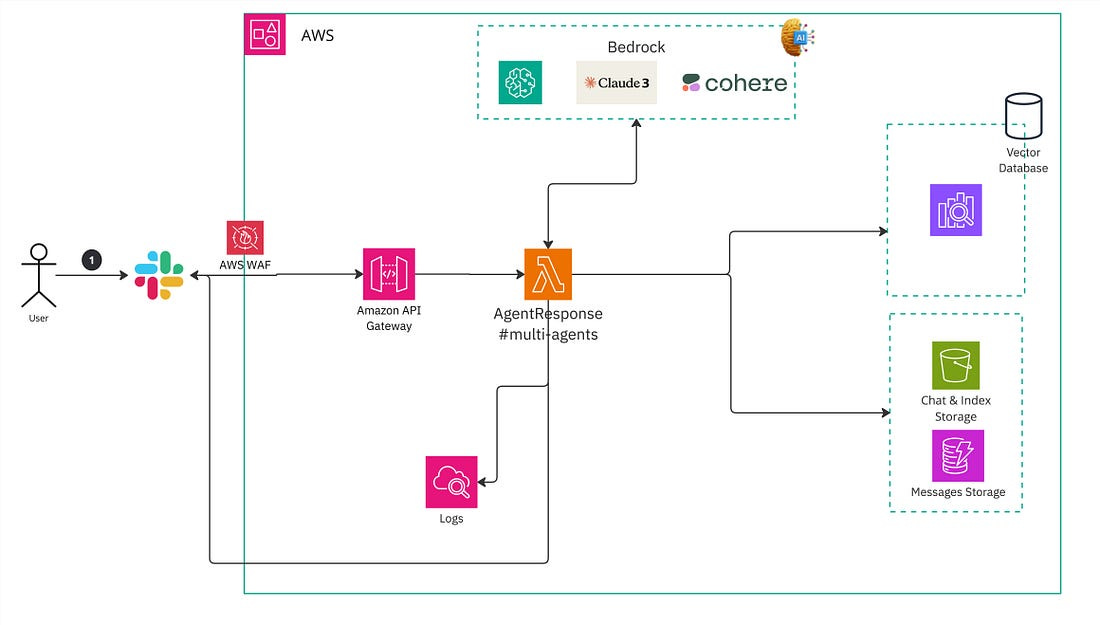
The workflow:
User sends a message to the Slack chat
Slack chat sends the message to the API Gateway Endpoint via Event Subscription
We have WAF to do the first layer of security. If the request is coming from our Slack channel, then forward the request to API Gateway.
The API then invokes the lambda function.
The lambda function converts user query into an embedding array via the Cohere embedding model from Bedrock.
The agent then conducts hybrid search against OpenSearch serverless to retrieve relevant data
The user query along with data retrieval, will be sent to LLM Bedrock to generate the response.
The response will be sent back to Slack bot UI
Of course, I have CloudWatch to logs for debugging and the DynamoDB to store all the chat conversations for purpose of fine-tuning later if needed.
The Slack bot app already maintains the chat history. The response from the Agent will appear as a thread under your original message, allowing you to easily follow up with your next question in the same thread. This enables the Agent to maintain context and history throughout the conversation.
Development Phase
Setting Up OpenSearch
I used AWS CDK to spin up the infrastructure for OpenSearch with private access via a VPC endpoint. This setup includes:
IAM Role: To define permissions and access controls.
Data Access Policy: To control who can read and write to the OpenSearch data.
Network Policy: To manage network access and ensure the VPC endpoint is secure.
Encryption Policy: To ensure all data is encrypted both at rest and in transit.
By doing this, I can control which applications have access to OpenSearch. Ideally, only AWS Bedrock and the Lambda Functions will have access.
Setting Up S3 Bucket
Again, I used AWS CDK to create an S3 bucket. This process was straightforward and simple. The S3 bucket will be used for storing any necessary data and configurations securely.
Preparing the Dataset
After downloading all the documents in HTML format, I needed to create embeddings for them. AWS Bedrock offered Titan and Cohere embedding models. I chose Cohere due to its availability in my AWS region, as AWS Titan Embedding was not yet ready in our region at the time of developing the first version.
HOWEVER, AWS AWS Bedrock offers a great tool called Knowledge Base. Essentially, you only need to put your data on S3, and the Knowledge Base will:
Connect the data from S3
Run embeddings of your choice
Insert, update, or delete embedding vectors in OpenSearch Serverless

This process is incredibly simple, eliminating the need to worry about the pipeline for creating, updating, or deleting vector indexes. It seems to be an excellent choice for our solution.
However, the only concern I had was the chunking strategy offered by AWS Bedrock Knowledge Base at the time. They provided two options:
FIXED_SIZE: Amazon Bedrock splits your source data into chunks of the approximate size you set in the
fixedSizeChunkingConfiguration.NONE: Amazon Bedrock treats each file as one chunk. If you choose this option, you may want to preprocess your documents by splitting them into separate files.
I knew that a simple strategy like FIXED_SIZE wouldn’t work well for data retrieval. However, I still wanted to test out this feature. Therefore, I decided to create two vector indexes:
Manual Embedding: I created a script to handle creating, updating, and deleting vector embedding data with hierarchical chunking using Cohere embeddings and LlamaIndex.
Knowledge Base Embedding: I used the FIXED_SIZE chunking strategy provided by Bedrock’s Knowledge Base.
This allowed me to compare the effectiveness of the two approaches and determine the best strategy for our needs.

After a few experiments comparing the performance of both approaches, I decided to go with manual embedding. While this approach introduces the complexity of writing a Python script to run daily for creating, updating, or deleting OpenSearch vector database entries, it provides better accuracy in data retrieval through hierarchical chunking and hybrid search.
The simplicity of Bedrock’s Knowledge Base setup was tempting, but I didn’t want to risk performance for an easier solution.
Soon, AWS will release additional features for Bedrock that will improve chunking. Until then, I will stick with my script to create embedding data.
LLM Model and Embedding Model
This is an easy choice. I use Claude 3 Sonnet from Anthropic and Cohere Embedding. All are available via AWS Bedrock in our region.
Developing the Slack App
There are multiple ways to set up a Slack chatbot, but I found that using event subscriptions was the easiest approach. The setup involved the following steps:
Setting Up a Lambda Function: Create a Lambda function that will handle the incoming Slack events.
Configuring API Gateway: Point the API Gateway to the Lambda function to serve as the endpoint for the Slack app.
Creating the Slack App: Visit Slack API to create a new Slack app.
Event Subscription:
Go to the Event Subscriptions section in your Slack app settings.
Enable event subscriptions and set the Request URL to the API Gateway endpoint configured earlier.
5. Configuring Event Subscriptions:
Select the events you want your Slack app to listen to and subscribe to them.
6. Configuring Permissions:
Ensure the Slack app has the necessary permissions to read and write messages in the channels where it will be used.
The OAuth and Permissions should look like this.

Under Event Subscription, the “Subscribe to bot events” should look like this:

The Lambda function contained the logic for our first agent, which accessed the OpenSearch embedding vector.
At this steps, what I have built and deployed so far.
S3 Bucket: Created via AWS CDK to store HTML files extracted from Confluence.
Data Extraction: Data from Confluence was extracted in HTML format and stored in the S3 bucket.
OpenSearch Serverless: Set up for the vector embedding database.
Python Script: Developed to run daily, handling the creation, update, and deletion of embedding data in the vector database.
Lambda Function: Contains the logic for the first agent, utilizing LlamaIndex as the main framework to access the OpenSearch embedding vector.
Slack Chatbot: Set up with event subscriptions, integrated with API Gateway and Lambda for event handling.
I have everything setup, the next step is to test it out.
First problem encounter.
Interestingly, the issue wasn’t with the logic or the agent but with Slack itself. I encountered a problem where my agent responded twice to a message. After a long day of investigation, I realized that the issue wasn’t with my Lambda function but rather with the configuration of Slack.
By default, when you send a message through your Slack bot, Slack sends that message to the API Gateway via event subscription. The API Gateway then invokes the Lambda function, which acts as the agent and retrieves the response. However, Slack expects to receive a success message within 3 seconds. If there is no response within that time frame, Slack sends another request, leading to duplicate responses. This happens because the Lambda function with a single agent typically takes more than three seconds to get the answer.
To overcome this limitation, I added another Lambda function to my existing architecture. This Lambda function serves as an immediate response handler and performs two crucial tasks:
Verification: It verifies if the request is coming from our Slack workspace based on the TeamID.
Asynchronous Processing: If the request is valid, it asynchronously triggers the main agent Lambda function and immediately returns a success message to Slack. This prevents duplicate responses by ensuring Slack receives a timely acknowledgment, avoiding the re-sending of the request.
So the new architect will look like this:
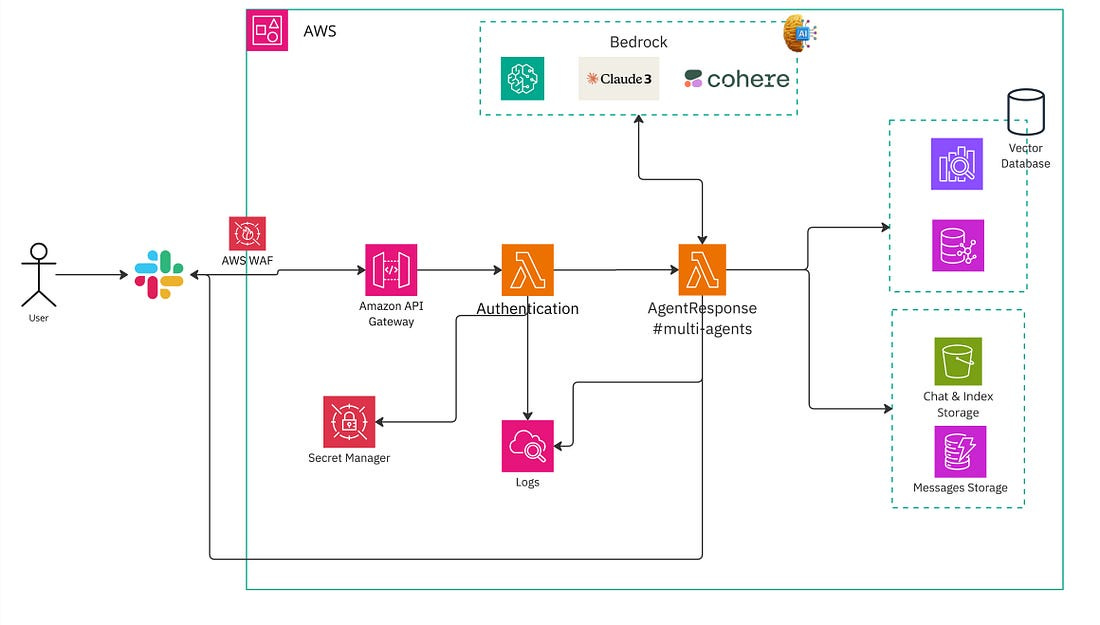
The workflow is following:
User sends a message to the Slack chat
Slack chat sends the message to the API Gateway Endpoint via Event Subscription
We have WAF to do the first layer of security. If the request is coming from our Slack channel then forward the request to API Gateway.
The API then invokes the ImmediateResponse.
The Immediate Response will do another verification layer. If the verification pass, then it invokes the Agent Response as well as returns the success status to Slack immediately.
The Agent lambda function converts the user query into an embedding array via the Cohere embedding model from Bedrock.
The agent then conducts a hybrid search against OpenSearch serverless to retrieve relevant data.
The user query, along with data retrieval, will be sent to LLM Bedrock to generate the response.
The response will be sent back to the Slack bot UI
Key Learnings and Pitfalls
What Worked:
Manual chunking with an advanced chunking algorithm was more effective than AWS Bedrock’s default mode.
Claude 3 Sonnet proved to be a reliable LLM model.
Tight control over Slack bot permissions is crucial to avoid unintended data access. This is a painful lesson for me. I didn’t know this when I started, and then I gave the bot too many missions, which made the bot read all the messages from another channel. Luckily, there was logging, and I saw the API was hit. Even though I didn’t send any message, I revoked those options immediately.
Cohere embedding is limited with 512 chunking max token (only AWS Titan embedding offers an 8k token chunking limit. However, it is not available in our region at the time of development)
The script for the embedding process to insert data into a vector database takes a lot of time. Eventually, I rewrote the script with multi-threading so it improved the speed by 8 times faster.
Don’t rely in a single agent, try a few data retrieval approaches, such as QueryFusion or Reranking and combine them to improve data retrieval.
A function calling agent with multi-tools with each tool is one data retrieval approach that works.
OpenSearch Serverless is a solid option.
Utilize the Slack thread to maintain the history of the conversation of the opening message
What Didn’t Work:
Default chunking was ineffective despite fast synchronization. The sync process from bedrock to sync data between S3 and OpenSearch is very fast (only a few minutes compared to ~15 minutes of my script, even with multi-threading)
The blank prompt for Agent is not working. Need to put on an engineering prompt to get the Agent to work well.
ReAct agent suffers from hallucinations.
Cohere’s 512 token limit was restrictive, making AWS Titan a better choice if available.
Conclusion
Although I plan to develop a multi-agent AI application, I am starting simply with a single agent for this proof of concept (PoC). I use a function-calling agent, with each function responsible for a specific data retrieval algorithm. This approach reduces the risk of hallucination common in ReAct agents and improves response accuracy.
Developing the multi-agent AI application with Slack integration was a rewarding experience. By leveraging existing tools like AWS Bedrock and Slack, we created a robust solution to streamline knowledge sharing within our organization.
The first version was released, and the initial users were very impressed. I enjoy receiving positive feedback from users, and appreciate it even more when they provide recommendations for improvement.
After all, developing a new internal application within a startup can be an enriching experience. You have a ready pool of users who are eager to use the product and provide valuable feedback. While it may not be exactly like starting a new company from scratch or as dramatized as in “Silicon Valley,” it still offers the experience and excitement of innovation.
Most importantly, I applied the Lean Startup principles to evaluate ideas and iterate on them from the feedback. This approach allowed me to learn and adapt quickly, ensuring the application met the users’ needs and expectations.
In the next post, I will talk about the second iteration of the bot which is SQL Agent. It all started with “Hey Ryan, awesome work with your AI bot. When we can use it to query our database”.
❤ If you found this post helpful, I’d greatly appreciate your support by giving it a clap. It means a lot to me and demonstrates the value of my work. Additionally, you can subscribe to my substack as I will cover more in-depth LLM development in that channel. If you have any questions, feel free to leave a comment. I will try my best to answer as soon as possible.
Want to Connect?
If you need to reach out, don't hesitate to drop me a message via my
Twitter or LinkedIn and subscribe to my Substack, as I will cover
more learning practices, especially the path of developing LLM
in depth in my Substack channel.References
All of my previous blog post of LLM: https://medium.com/@ryanntk/all-of-my-llm-and-rag-articles-c4b0848b0a21
Agentic Approach with LlamaIndex: https://docs.llamaindex.ai/en/stable/use_cases/agents/
Hey Ryan, curious on your take on using Slack for multi-agent orchestration and how it will manage context switching. For example, we have the conversation history all in one continuous thread, but in web based UI (e.g., chatgpt) you can organize conversations by topic, etc. I imagine this becomes even more important in a multi-agent world. Thoughts on how you think slack integration can tackle this?