
SQL Generator 2.0: How I build AI Query Wizard for Enterprise-Scale with 500+ Tables
How I Turned Natural Language into SQL AI Magic for Enterprise-Scale Database

This is part 3 of the series of how I built this. Beyond the simple text-to-SQL and enterprise scale
Previous Posts:

The Journey So Far: Recap of the Confluence Agent
Before we dive into the SQL Agent, let’s briefly revisit the Confluence Agent we developed:
Metadata Ingestion: Capturing the structure of our knowledge base.
Content Extraction: Pulling in the meat of our documentation.
Format Handling: Separating HTML and PDF content for optimal processing.
Image Analysis: Leveraging LLM parsing to extract and understand image content.
Performance Boost: Implementing async and multi-threading for a 10x speed improvement.
These enhancements laid the groundwork for a robust information retrieval system. Now, we’re expanding our toolkit to tackle one of the most common challenges in data-driven organizations: SQL query generation.
Why do I build this?
Imagine this scenario: You’re a new data analyst, and your boss drops by your desk with an urgent request:
“I need a comparative analysis of yesterday’s game metrics against last year’s data, focusing on velocity and revenue. Have it on my desk by EOD.”
As the colour drains from your face, you realise you’re facing several challenges:
You’re new and don’t know where to find the relevant data.
You’re not sure which tables contain the information you need.
Writing complex SQL queries isn’t your strong suit (yet).
Your manager is in meetings all day, and you don’t want to bombard them with basic questions
This scenario highlights three critical challenges many organizations face:
Data Volume: With over 500 tables spanning traditional and modern data warehouses, finding the right data can be like searching for a needle in a haystack.
Query Complexity: Serving as the single source of truth means fielding complex queries from various departments.
Knowledge Gap: New team members often struggle to navigate vast databases without extensive institutional knowledge.
I’ve been thinking about this for awhile but never had a thought to start working on it until a perfectly normal morning where I had a casual conversation with my General Manager.
“Can we query the data from your chatbot now?’”
Little did I know, this off-the-cuff comment would send me on a quest to revolutionize how we interact with our data. But before I get into how I built this AI query wizard, let me spill the tea on why most solutions out there just don’t cut it for enterprise-scale problems.
Why “Just Google It” Doesn’t Work for Enterprise SQL Challenges
Before rolling up my sleeves, I did what any self-respecting dev would do: I scoured the internet for solutions. What I found was… well, let’s just say it left a lot to be desired.
The “Hello World” of Text to SQL
Most articles and tutorials I found were like trying to use a kiddie pool to train for the Olympics:
🐣 Tiny Table: Examples using 2–3 tables. Cute, but our smallest schema would eat those for breakfast.
📜 The Scroll of Infinite Prompts: Solutions suggesting I paste entire table schemas into prompts. Good luck looking at the infinite prompts.
🏝️ Isolated Island Queries: Simple queries on single tables, ignoring the complex relationships in real databases.
🐌 Performance? What Performance?: Most examples neglect the crucial aspect of query performance in large datasets.
My Data Reality
While these tutorials were paddling in the kiddie pool, I was staring at the data equivalent of the Pacific Ocean:
🏙️ Table Chaos: Over 300 tables, some with more 150 columns
🕸️ Complicated Relationship: A data model with complex interdependencies, it is Data Vault modelling.
🏎️ Need for Speed: Queries that need to be optimized for speed and efficiency.
🔄 Evolving Schemas: A dynamic environment where table structures change frequently.
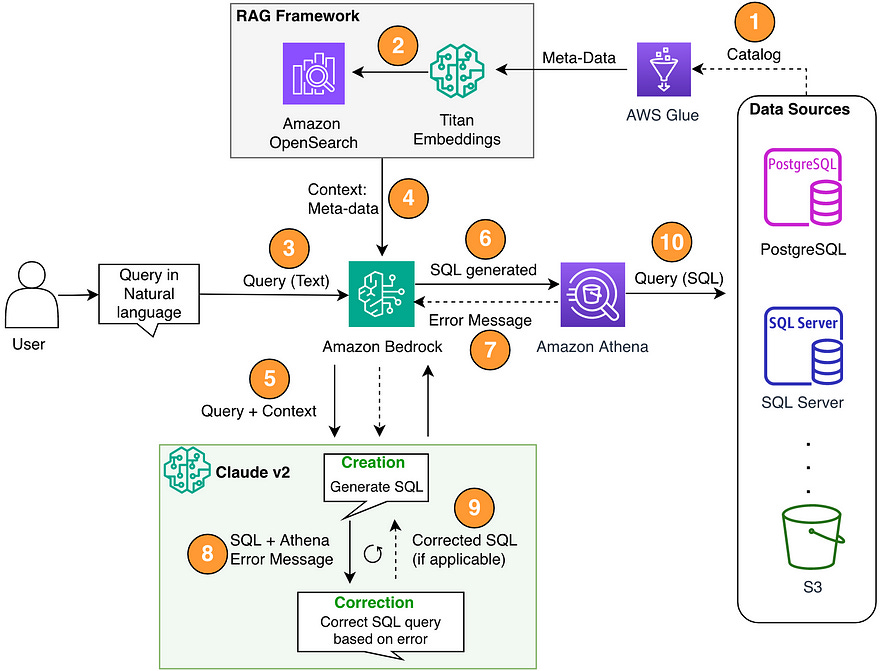
It was clear: we needed a solution as robust and sophisticated as our data environment.
Implementing the SQL Agent
Let’s not waste time and get right into it. Now, here is a constraint.
I obviously can give the SQL Agent the ability to execute the SQL. In fact, I should, however, as this is PoC, the API key to interact with database is under my name and it is easy for someone can just come in and do prompt injection to say “DROP THE TABLE”. Moreover, I don’t guaranty that the SQL generated from the agent is 100% correct and optimised. With more and more training data, eventually, we will get to that stage soon. For now, it is up to user to verify the SQL generated.
The current high level architect
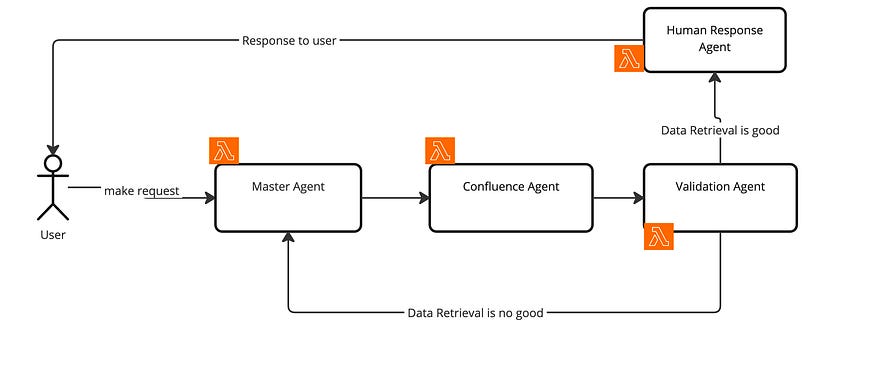
We only have one single agent at the moment. The Confluence Agent. The workflow remain the same. User send a request -> it is send to master agent to do reasoning -> send to confluence agent to find the answer with confluence knowledge base -> send to validation agent to validate the response -> send to human response agent to mark the PII data if there is and response to the user, otherwise, call master agent and ask for reevaluate as the data retrieval is not good enough.
Data Processing: The Foundation of Success
You won’t have good result if you just dump plain text into vector database and expect the LLM to do a good job. I tried and failed so you don’t have to try by yourself. Any successfully machine learning system or LLM/Gen AI system hinge on the data processing. This is crucial step and always take up more than 80% of the time. If you have your data right, then the prompt engineer can be taken later. Don’t try to prompt engineer over data preparation.
1. Data Ingestion: Mapping the Data Landscape
First things first, I needed to get a grip on our massive data landscape. Our data platform use AWS Glue as the main data catalog, so Glue always contain the latest update of the table/database/schema.
This step was crucial because it laid the foundation for everything that followed.
I wrote a Python script that interfaced with the AWS Glue API to pull information about all our databases and tables. This wasn’t just a simple data dump — I had to carefully structure the extracted information to make it usable for the later stages of the project.
import boto3
session = boto3.Session(profile_name='<your_profile_name>')
glue_client = session.client('glue')
bedrock_runtime = session.client(service_name='bedrock-runtime')
def list_glue_tables(glue_client):
raw_all_tables = []
filtered_databases = ['<your_db1>','<your_db_2>','<your_db_3>']
paginator = client.get_paginator('get_databases')
for page in paginator.paginate():
for database in page['DatabaseList']:
if database['Name'] not in filtered_databases:
continue
table_paginator = client.get_paginator('get_tables')
for table_page in table_paginator.paginate(DatabaseName=database['Name']):
raw_all_tables.extend(table_page['TableList'])
return raw_all_tablesThe script iterates through each database, then each table within those databases, extracting key information such as table names, column names and types, storage locations, and last update timestamps. This comprehensive approach ensured that no table was left behind, giving me a complete map of our data terrain.
def extract_schema(table):
return {
"DatabaseName": table['DatabaseName'],
"TableName": table['Name'],
"TableDescription": table.get('Description', ''),
"Partition": table.get('PartitionKeys', None),
"TableSchema": [
{
"Name": col['Name'],
"Type": col['Type'],
"Comment": col.get('Comment', '')
} for col in table['StorageDescriptor']['Columns']
],
"CreateTime": table.get('CreateTime', None),
"UpdateTime": table.get('UpdateTime', None),
"SourceSQL": table.get('ViewExpandedText', '')
}
def process_table(table):
print(f"Processing table {table['Name']}")
schema = extract_schema(table)
documentation = generate_documentation(schema) # find this function below
table_name = f"{table['DatabaseName']}.{table['Name']}"
save_documentation(table_name, documentation)
print(f"===Documentation generated for {table['Name']}")2. Contextual Enrichment: Adding Flavor to Raw Data
Raw table schemas are like unseasoned food — functional, but not very exciting. I needed to add some context, some spice to this data. This is where things got interesting, and where I started to leverage the power of Large Language Models (LLMs).
I developed an LLM-powered enrichment process that would take the raw metadata for each table and generate meaningful context. This wasn’t just about restating what was already in the metadata — I wanted the LLM to make educated guesses about the table’s purpose, its relationships to other tables, and how it might be used.
def generate_documentation(schema):
system_prompt = """
You are an expert database and business developer specializing in <place holder for your purpose>
Your task is to review database schemas and generate comprehensive documentation in JSON format.
Focus on providing insights relevant to the betting industry, including table purposes, column descriptions,
and potential use cases. Be concise yet informative, and ensure all output is in valid JSON format.
"""
initial_user_prompt = f"""
Please generate comprehensive documentation for the following database schema in JSON format only.
The documentation should include:
1. A brief overview of the table's purpose and its role in <purpose>
2. Detailed descriptions of each column, including its data type, purpose, and any relevant notes specific to the <your data platform>
3. Any additional insights, best practices, or potential use cases for this table in the context of <your context>
4. Comments on the creation and last update times of the table, if relevant to its usage or data freshness
5. Generate at least 10 common queries that could be run against this table in the context <your context>
Here's the schema:
{json.dumps(schema, indent=2, cls=DateTimeEncoder)}
Please provide the output in the following format:
```json
{{
"DatabaseName": "Name of the database",
"TableName": "Name of the table",
"TableDescription": "Brief overview of the table",
"CreateTime": "Raw creation time of table",
"UpdateTime": "Raw updated time of table",
"Columns": [
{{
"name": "column_name",
"type": "data_type",
"description": "Detailed description and purpose of the column"
}},
// ... all other columns
],
"AdditionalInsights": [
"Insight 1",
"Insight 2",
// ... other insights
],
"CommonQueries": [
{
"natural_language": "Nature english query",
"sql_query": "Detail of SQL query",
}
]
}}
```
If you need more space to complete the documentation, end your response with "[CONTINUE]" and I will prompt you to continue.
"""
full_response = ""
conversation_history = f"{system_prompt}\n\nuser: {initial_user_prompt}\n\nassistant: "
while True:
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"messages": [{"role": "user", "content": conversation_history}],
"max_tokens": 8192,
"temperature": 0,
})
response = bedrock_runtime.invoke_model(body=body, modelId=model_id)
response_body = json.loads(response.get('body').read())
current_response = response_body['content'][0]['text']
full_response += current_response
if response_body['stop_reason'] != 'max_tokens':
break
conversation_history += current_response
conversation_history += "\n\nuser: Please continue the JSON documentation where you left off, maintaining the perspective of an expert in sports and racing betting platforms.\n\nassistant: "
return full_responsePrompt engineering was crucial for this step. I had to craft prompts that would guide the LLM to provide:
A detailed description of what the table likely represents in our business context.
Potential use cases for the table, thinking about how different departments might query it.
Possible relationships with other tables, helping to map out our data model.
Any data quality considerations, like potential null values or data type inconsistencies.
Suggested partition keys for large tables, thinking about query optimization.
Potential unique identifiers, which would be crucial for join operations later on.
Here is the key:
At the time of working on this, Claude model via Bedrock only support up to 4096 output token. It is enough for majority of the use case, however, for some special table that contain more than 100 columns, it may result error. To handle this limitation, we will first see if the response from the first output contains max_token as stop_reason. If not, then continue with the process, but if max_token present then you need to send the existing response a long with tweak prompt to ask LLM to keep generating from previous step.
Remember: context token is 200k and output token is only 4096k.
There may be the case where the final output cannot be parse to JSON due to some malfunction. So we need to write this error into a txt file for reviewing later.
def save_documentation(table_name, documentation):
try:
json_content = documentation.split("```json")[1].split("```")[0].strip()
parsed_json = json.loads(json_content)
with open(f"{folder}/table_json/{table_name}.json", "w") as f:
json.dump(parsed_json, f, indent=2)
print(f"===Documentation saved for {table_name}")
except Exception as e:
print(f"===Error parsing documentation for {table_name}: {str(e)}")
with open(f"{folder}/{table_name}_doc_raw.txt", "w") as f:
f.write(documentation)
print(f"===Raw documentation saved for {table_name}")And here is the function to store the schema
def process_table(table):
print(f"Processing table {table['Name']}")
schema = extract_schema(table)
documentation = generate_documentation(schema)
table_name = f"{table['DatabaseName']}.{table['Name']}"
save_documentation(table_name, documentation)
print(f"===Documentation generated for {table['Name']}")3. Dual Indexing: Creating the Perfect Blend
I started with normal Vector Index with basic fix chunking but the result was bad, the SQL generator often get incorrect table name and column name. It does not have the full context as the chunking chop it out.
To remedy this, I moved away from normal chunking algorithm to hierarchical chunking approach and slightly change the prompt. This result better response and fix all the issue of the first approach.
But then the Vector Index left out on of the crucial aspect, it is relationship between the tables. For this, I use knowledge graph and the result was awesome.
In summary, we have 2 indexing approach:
Vector Index
The vector index was all about speed. I used the OpenSearch serverless as vector database and use hierarchical chunking as the chunking algorithm.
Knowledge Graph
While the vector index gave us speed, the knowledge graph provided depth. I used NetworkX to create a graph representation of our entire data model. Each table became a node, with edges representing relationships between tables.
The tricky part was in defining these relationships. Some were obvious, like foreign key relationships, but others required more nuanced understanding of our data model. I implemented logic to infer relationships based on naming conventions, common prefixes, and the enriched metadata from step 2.
This knowledge graph became the backbone of our system’s ability to understand complex, multi-table queries. It allowed the SQL Agent to “think” about data in terms of relationships and paths, much like a human data analyst would.
4. The Magic Brew: Translating Questions to SQL
Now, for the biggest part, the SQL Agent itself. As you already know, LlamaIndex is always my first choice when coming to developing AI Agent. I’ve used LangChain and other open-sources, while the LangChain is mature and have bigger community support, it tends to increase the unnecessary of complexity sometime.
Here is the implementation of SQL Agent
The prompt
def sql_agent_promt():
return """
You are an advanced AI assistant specialized in data analytics for <your domain database> with expert proficiency in Databricks Delta SQL.
Your primary role is to translate natural language queries into precise, executable SQL queries.
Follow these instructions meticulously:
Core Responsibilities:
- Always respond with an executable SQL query.
- Do NOT execute SQL queries; only formulate them.
- Utilize the vector database to access accurate schema information for all tables.
Process:
1. Understand User Input:
- Interpret the user's natural language query to comprehend their data requirements and objectives.
2. Retrieve Relevant Tables:
- Identify and retrieve the most relevant tables from the vector database that align with the user's query.
- Continue this step until you find all necessary tables for the query.
3. Verify Schema:
- For each relevant table, retrieve and confirm the exact schema.
- IMPORTANT: Pay special attention to column names, data types, and relationships between tables.
4. Formulate SQL Query:
- Construct a Databricks Delta SQL query using the confirmed schema information.
- Ensure all table and column names used in the query exactly match the schema.
5. Provide Professional Response
- Draft the SQL query as a seasoned senior business analyst would, ensuring clarity, accuracy, and adherence to best practices.
6. (Optional) Explanation
- If requested, provide a detailed explanation of the SQL query and its logic.
Response Format:
1. Begin with the SQL query enclosed in triple backticks (```).
2. Follow with a brief explanation of the query's purpose and how it addresses the user's request.
3. Include a schema confirmation section, listing the tables and columns used.
Guidelines:
- Prioritize query accuracy and performance optimization.
- Use clear and professional language in all responses.
- Offer additional insights to enhance user understanding when appropriate.
Error Handling:
If you lack information or encounter ambiguity, use the following format:
<clarification_request>
I need additional information to formulate an accurate query. Could you please:
- Provide more details about [specific aspect]?
- Confirm if the following tables and columns are relevant: [list potential tables/columns]?
- Clarify any specific time ranges, filters, or conditions for the data?
</clarification_request>
Schema Confirmation
Before providing the final query, always confirm the schema:
<schema_confirmation>
I'll be using the following schema for this query:
Table: [table_name1]
Columns: [column1], [column2], ...
Table: [table_name2]
Columns: [column1], [column2], ...
Are these the correct tables and columns for your query?
</schema_confirmation>
Example Response
<give your example here>
Remember to maintain a professional, clear, and helpful tone while engaging with users and formulating queries.
"""The process works like this:
When a user submits a query, we first use the vector index to quickly identify potentially relevant tables and columns.
We then consult the knowledge graph to understand the relationships between these tables and to identify any additional tables that might be needed to answer the query.
Using this information, we construct a prompt for the LLM that includes:
The user’s original query
Information about the relevant tables and columns
Context from our knowledge graph and vector database about how these tables relate to each other
Any specific business rules or common practices we’ve encoded
The LLM then generates a SQL query based on this information.Finally, we run the query through a validation step to catch any obvious errors or inefficiencies.
Here is the code for agent:
Remember the knowledge base we’ve created above, we use it as tools in this agent
response_synthesizer = get_response_synthesizer(llm=llm)
query_engine = RetrieverQueryEngine(
retriever=sql_knowledgebase,
response_synthesizer=response_synthesizer,
)
query_engine_tools = [
QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name="database_retriever",
description="Have access to data catalog, that have all details about databases, schemas, tables, table columns and its attribute along with description."
),
),
...... <second tool for knownledge graph>
]
agent_worker = FunctionCallingAgentWorker.from_tools(
query_engine_tools,
llm=llm,
verbose=True,
allow_parallel_tool_calls=True,
system_prompt=sql_agent_promt()
)
agent = agent_worker.as_agent(memory=chat_memory)The prompt engineering for this step was the most challenging of all. I had to create a prompt that would guide the LLM to write correct, efficient SQL while also explaining its reasoning. This explanation component was crucial for building trust with users and helping them understand the generated queries.
The Result: A Data Wizard That Never Sleeps
My SQL Agent turned out to be the MVP I never knew I needed. It’s like having a 24/7 data concierge who never gets your order wrong.
The high-level multi-agents architect now

As you can see, we have another agent in the rectangle box. We now have 2 agents that contanstly talking to each other to resolve user query as long as the query is about the generating SQL or general question based on Confluence documents.
Lessons Learned
Throughout this journey, I learned some valuable lessons that I think could benefit anyone working on similar projects:
Context is King: Understanding table contexts and relationships is key to generating accurate queries.
Graph-Based Approach: The knowledge graph approach handles complex queries better than normal index. It allowed the system to “think” about data relationships in a way that closely mimics human reasoning.
Continuous Learning: I have constantly feeding new queries back into our system to improve its performance.
Explainability is Essential: Having the system explain its reasoning builds trust with users and helps them learn about the data model. It’s like a chef explaining the ingredients in a complex dish.
Edge Cases are the Spice of Life: Handling edge cases and unusual queries was often where the most interesting insights came from. It forced me to think deeply about our data model and how users interact with it.
Conclusion
My journey from a casual comment to a sophisticated SQL Agent shows that with the right mix of technology, creativity, and a dash of caffeine-induced inspiration, we can solve even the most complex data challenges.
I’ve created more than just a tool; I’ve cooked up a whole new way of interacting with data. It’s democratizing access to insights, making every team member a potential data gourmet.
If you have any question or want to know more about the details of the implementation, feel free to leave the comment below or reach out to me directly.
❤ If you found this post helpful, I’d greatly appreciate your support by giving it a clap. It means a lot to me and demonstrates the value of my work. Additionally, you can subscribe to my substack as I will cover more in-depth LLM development in that channel. If you have any questions, feel free to leave a comment. I will try my best to answer as soon as possible.
Want to Connect?
If you need to reach out, don't hesitate to drop me a message via my
Twitter or LinkedIn and subscribe to my Substack, as I will cover
more learning practices, especially the path of developing LLM
in depth in my Substack channel.References
All of my previous blog posts of LLM: https://medium.com/@ryanntk/all-of-my-llm-and-rag-articles-c4b0848b0a21
Agentic Approach with LlamaIndex: https://docs.llamaindex.ai/en/stable/use_cases/agents/
https://medium.com/pinterest-engineering/how-we-built-text-to-sql-at-pinterest-30bad30dabff
Great post Ryan. Would be amazing if you can share a story about actual agents what are prompts/logic for the master and validation agent
I would have liked to see a few examples of the results.